一、欠拟合与过拟合任务简介
1、欠拟合和过拟合是什么
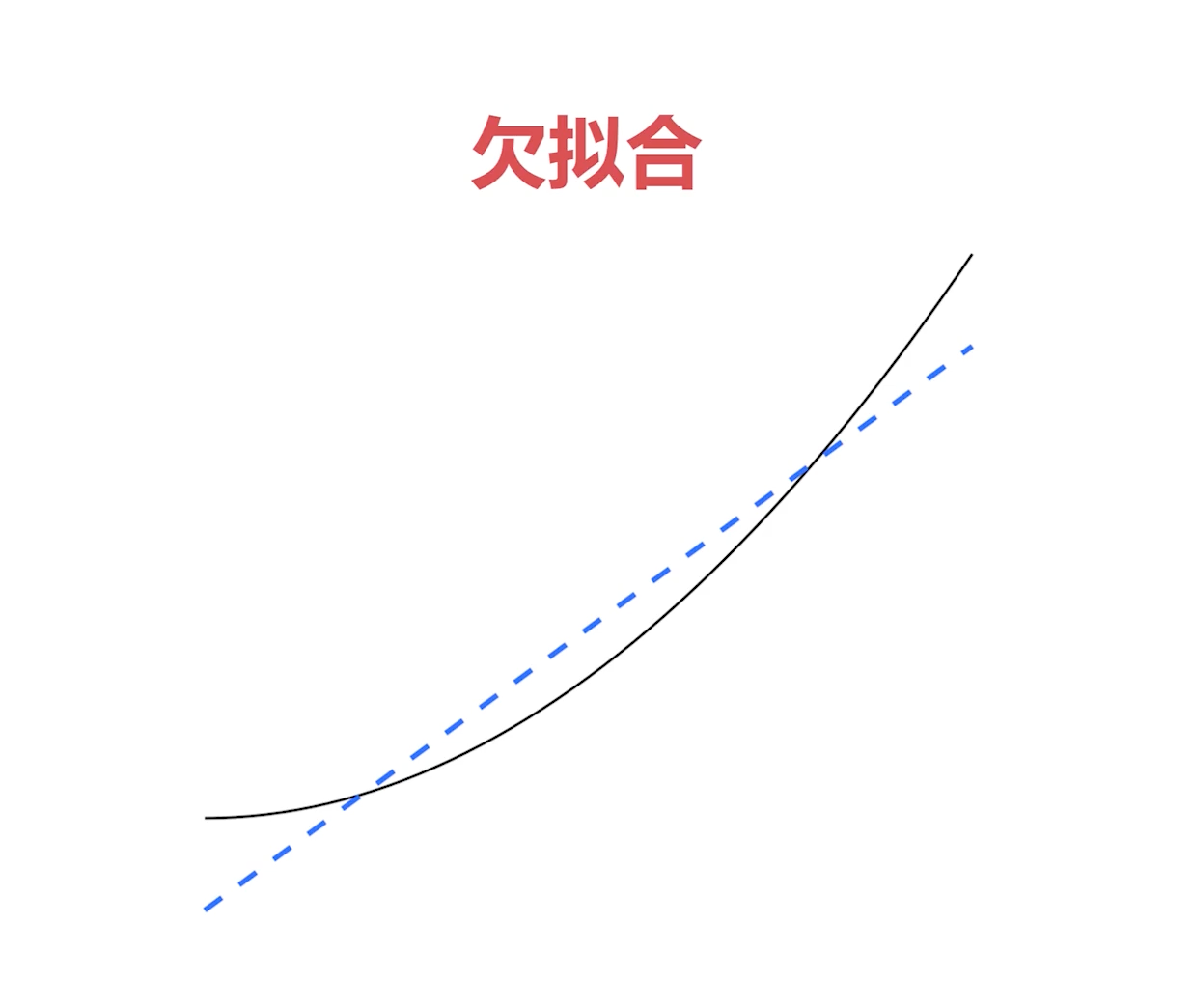
(1)欠拟合
欠拟合简单来说就是数据很复杂,但是你的模型太简单了,拟合不了这个数据,这就是欠拟合。比如说下面这张图,黑色的线就代表数据是一条弧线,我们的数据分布是一条弧线,而蓝色的线则就是我们的模型,模型则是一个简单的线性模型,就是一条直线。显然这个蓝色的模型是不能拟合黑色线的数据的,这种情况下就是欠拟合。
(2)过拟合
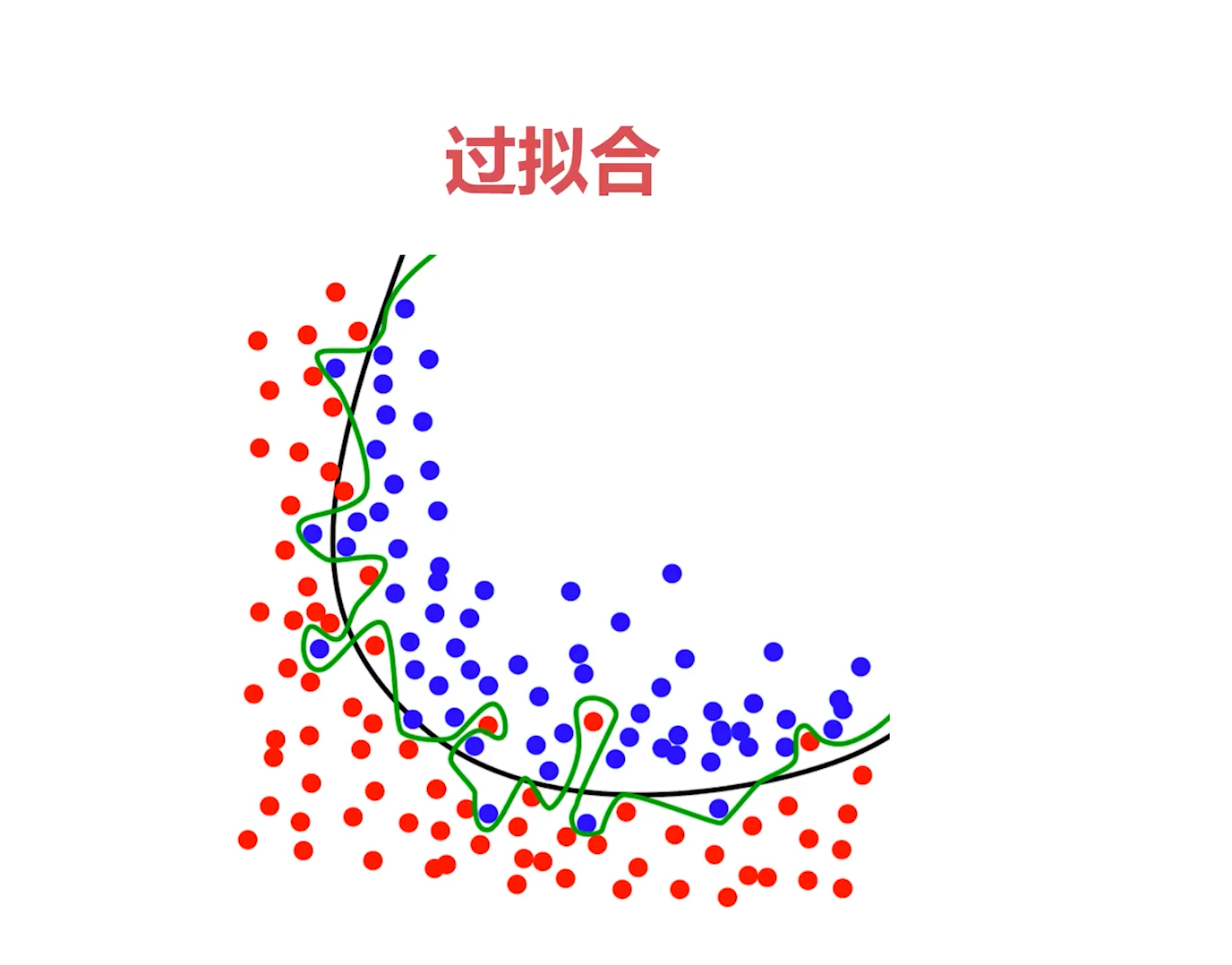
过拟合想要表达的就是说我们的模型太过复杂了,太过强大了,导致于我们把数据给拟合过头了,反而遇到额外的数据或者新的数据,结果就表现的不是很好。
比如下面这张图,红色的点和蓝色的点分别代表两类数据,就是这是一个二分类数据集,这个黑色的线代表一个比较正常的一个模型,它把红色和蓝色的线分开了,大部分都分开了,而且这个模型应该是一个表现不错的模型。
而绿色的线就是一个过拟合的模型,这个绿色的线,它想方设法把红色和蓝色分开,你看它把几乎所有的这个蓝色的点,红色的点,这蓝色的点,它都拐着弯儿想方设法把它给分开,这样它的训练损失才会降低,对吧?
但是它为了这么做,会导致一个后果,就是它最终呈现的形态是非常混乱的。而这么一个看起来这么复杂的模型,其实有可能只需要用一个简单的二分类数据,用一个弧线就能做到的,平滑的弧线就可以分开来。
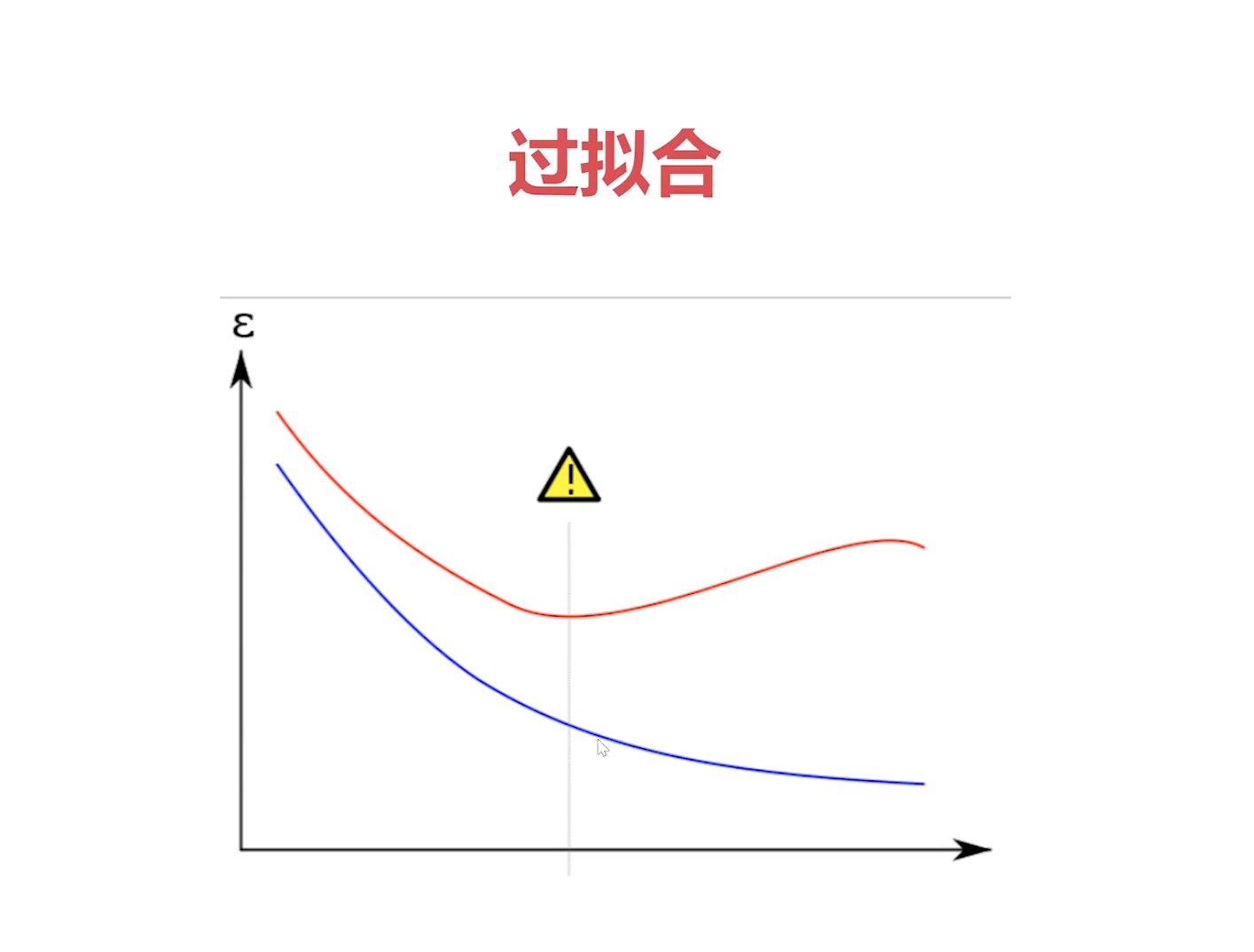
因此,这个模型去预测新数据或者验证集上的数据的时候,它的损失就不一定低,有可能损失会很高,这就是过拟合。
2、操作步骤
下面我们来说说,解决欠拟合和过拟合的一些操作步骤。具体如下:
- 加载带有噪音的二分类数据集(训练集和验证集)
- 使用不同神经网络演示欠拟合和过拟合
- 过拟合应对法:早停法、权重衰减、丢弃法
二、加载带有噪音的二分类数据集
1、为什么要加载带有噪音的二分类数据集
这是因为稍微带一点噪音更容易复现过拟合的现象。因为过度复杂的模型,为了拟合所有的训练集的数据,他把那一丁点噪音也给过度拟合掉了。
他为什么能把那一丁点噪音也给拟合掉呢?那些噪音不是非常的不规则,非常的复杂吗?
正是因为我们的模型足够复杂,所以这个模型它有能力去拟合那些噪音。虽然它有能力,但这显然不是我们想要的结果,因为最终生成的模型会非常复杂,然后面对训练集以外的数据时,反而预测得非常不好了。因为我们这个问题很简单,就是一刀切二分类结果,它生成一个非常复杂的模型,自然是在二分类数据集上表现不好的,这就是典型的一个过拟合现象。
2、操作步骤
- 使用预先准备好的脚本加载带有噪音的二分类数据集
- 可视化数据集
三、使用简单神经网络演示欠拟合
1、操作步骤
- 加载非线性的XOR数据集 —— 为什么要加载这个
XOR数据集呢?因为XOR问题是一个复杂问题,只有用简单模型去解决复杂问题的时候,才会造成欠拟合,因此我们需要加载一个稍微复杂一点的非线性的 XOR 数据集,然后用简单的模型去拟合它。 - 使用单个神经元组成的神经网络演示欠拟合 —— 前面我们谈到过,如果想解决非线性问题,必须要使用多层神经网络,至少得两层配合激活函数才可以。所以说这个单个神经元组成的神经网络肯定是拟合不了这个复杂问题的,这就属于一个欠拟合的过程了。
2、训练过程
首先,我们先创建一个data.js文件,功能主要用来加载训练数据集。
/**
*
* @param {*} numSamples 放多少样本量
* @param {*} variance 方差
* @returns
*/
export function getData(numSamples, variance) {
let points = [];
function genGauss(cx, cy, label) {
for (let i = 0; i < numSamples / 2; i++) {
let x = normalRandom(cx, variance);
let y = normalRandom(cy, variance);
points.push({ x, y, label });
}
}
genGauss(2, 2, 1);
genGauss(-2, -2, 0);
return points;
}
/**
* Samples from a normal distribution. Uses the seedrandom library as the
* random generator.
*
* @param mean The mean. Default is 0.
* @param variance The variance. Default is 1.
*/
// 正态分布
function normalRandom(mean = 0, variance = 1) {
let v1, v2, s;
do {
v1 = 2 * Math.random() - 1;
v2 = 2 * Math.random() - 1;
s = v1 * v1 + v2 * v2;
} while (s > 1);
let result = Math.sqrt((-2 * Math.log(s)) / s) * v1;
return mean + Math.sqrt(variance) * result;
}/**
*
* @param {*} numSamples 放多少样本量
* @param {*} variance 方差
* @returns
*/
export function getData(numSamples, variance) {
let points = [];
function genGauss(cx, cy, label) {
for (let i = 0; i < numSamples / 2; i++) {
let x = normalRandom(cx, variance);
let y = normalRandom(cy, variance);
points.push({ x, y, label });
}
}
genGauss(2, 2, 1);
genGauss(-2, -2, 0);
return points;
}
/**
* Samples from a normal distribution. Uses the seedrandom library as the
* random generator.
*
* @param mean The mean. Default is 0.
* @param variance The variance. Default is 1.
*/
// 正态分布
function normalRandom(mean = 0, variance = 1) {
let v1, v2, s;
do {
v1 = 2 * Math.random() - 1;
v2 = 2 * Math.random() - 1;
s = v1 * v1 + v2 * v2;
} while (s > 1);
let result = Math.sqrt((-2 * Math.log(s)) / s) * v1;
return mean + Math.sqrt(variance) * result;
}接着,创建一个 script.js 文件,具体训练代码如下:
import * as tf from '@tensorflow/tfjs';
import * as tfvis from '@tensorflow/tfjs-vis';
import { getData } from './data';
window.onload = async () => {
const data = getData(200, 2);
tfvis.render.scatterplot(
{ name: '训练数据' },
{
values: [
data.filter((p) => p.label === 1),
data.filter((p) => p.label === 0)
]
}
);
const model = tf.sequential();
// 增加层,让神经网络更复杂点
// 过拟合演示
// model.add(
// tf.layers.dense({
// units: 10,
// inputShape: [2],
// activation: 'tanh'
// // kernelRegularizer: tf.regularizers.l2({ l2: 1 })
// })
// );
// model.add(tf.layers.dropout({ rate: 0.9 }));
// model.add(
// tf.layers.dense({
// units: 1,
// activation: 'sigmoid'
// })
// );
// 欠拟合演示
model.add(
tf.layers.dense({
units: 1,
inputSize: [2],
activation: 'sigmoid'
})
);
model.compile({
loss: tf.losses.logLoss,
optimizer: tf.train.adam(0.1)
});
// 一个长度为2的一维数组
const inputs = tf.tensor(data.map((p) => [p.x, p.y]));
// 指定label,将其转换为tensor
const labels = tf.tensor(data.map((p) => p.label));
await model.fit(inputs, labels, {
validationSplit: 0.2, // 验证集分出20%
epochs: 200, //
callbacks: tfvis.show.fitCallbacks(
{ name: '训练效果' },
['loss', 'val_loss'], // 训练损失和验证的损失
{ callbacks: ['onEpochEnd'] }
)
});
};import * as tf from '@tensorflow/tfjs';
import * as tfvis from '@tensorflow/tfjs-vis';
import { getData } from './data';
window.onload = async () => {
const data = getData(200, 2);
tfvis.render.scatterplot(
{ name: '训练数据' },
{
values: [
data.filter((p) => p.label === 1),
data.filter((p) => p.label === 0)
]
}
);
const model = tf.sequential();
// 增加层,让神经网络更复杂点
// 过拟合演示
// model.add(
// tf.layers.dense({
// units: 10,
// inputShape: [2],
// activation: 'tanh'
// // kernelRegularizer: tf.regularizers.l2({ l2: 1 })
// })
// );
// model.add(tf.layers.dropout({ rate: 0.9 }));
// model.add(
// tf.layers.dense({
// units: 1,
// activation: 'sigmoid'
// })
// );
// 欠拟合演示
model.add(
tf.layers.dense({
units: 1,
inputSize: [2],
activation: 'sigmoid'
})
);
model.compile({
loss: tf.losses.logLoss,
optimizer: tf.train.adam(0.1)
});
// 一个长度为2的一维数组
const inputs = tf.tensor(data.map((p) => [p.x, p.y]));
// 指定label,将其转换为tensor
const labels = tf.tensor(data.map((p) => p.label));
await model.fit(inputs, labels, {
validationSplit: 0.2, // 验证集分出20%
epochs: 200, //
callbacks: tfvis.show.fitCallbacks(
{ name: '训练效果' },
['loss', 'val_loss'], // 训练损失和验证的损失
{ callbacks: ['onEpochEnd'] }
)
});
};最后,我们来看下训练效果。如下图所示:
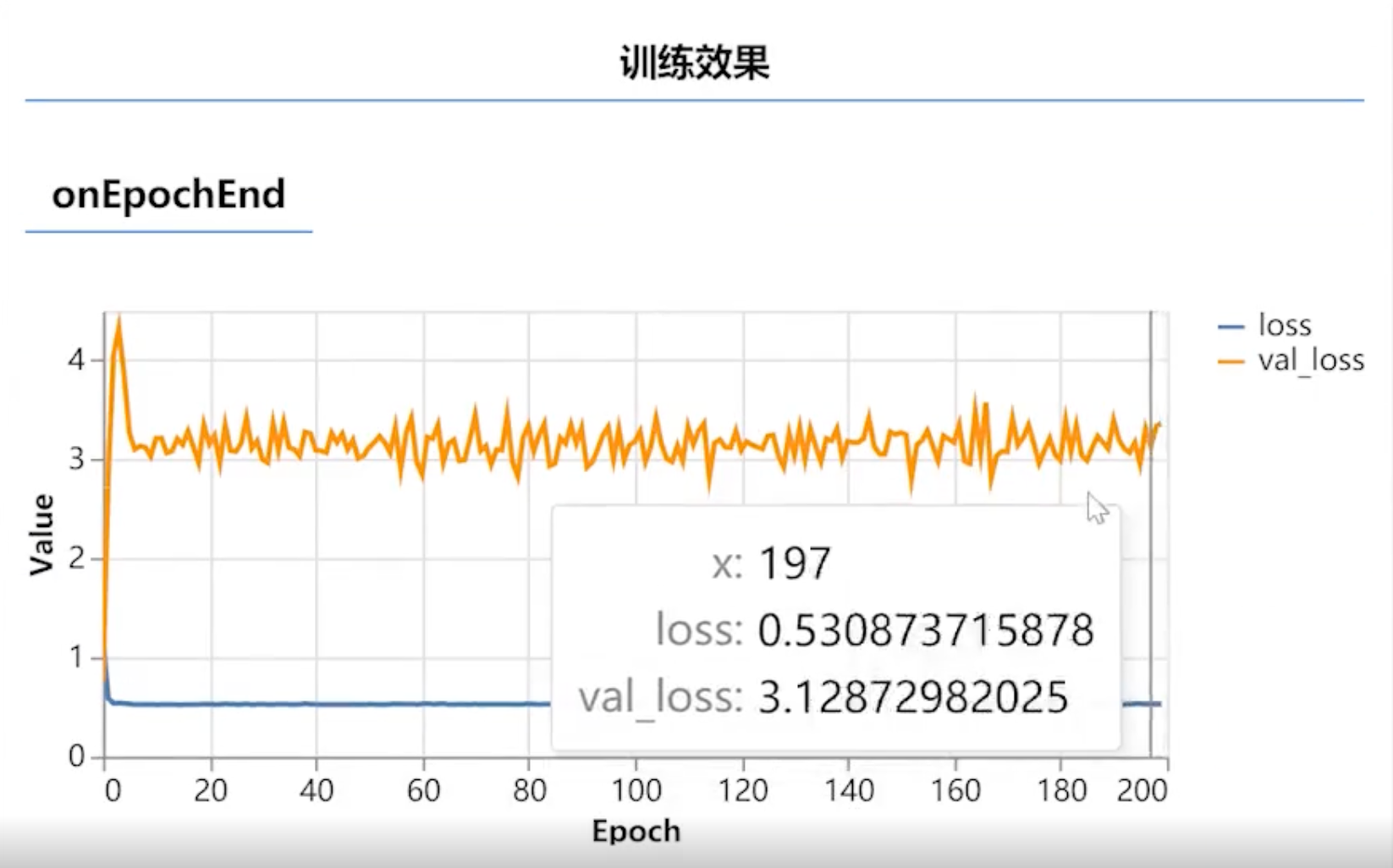
可以看到,蓝色的线一直0.5,降不下去。这就说明了模型处于一个欠拟合的状态。
一般来说,我们训练XOR的时候,它是可以把损失值降到非常低的,但这里一直是0.5,算是一个比较高的值了。
3、遇到欠拟合该怎么办?
下面我们来梳理下,遇到欠拟合的情况该怎么办?一般来说,可以通过增加模型的复杂度,添加更多的层,添加更多的神经元去尝试。
四、使用复杂神经网络演示过拟合
1、操作步骤
- 加载带有噪音的二分类数据集
- 使用多层神经网络演示过拟合
2、训练过程
在上面训练的基础上,我们来增加更多的层数,演示过拟合效果。如下代码所示:
import * as tf from '@tensorflow/tfjs';
import * as tfvis from '@tensorflow/tfjs-vis';
import { getData } from './data';
window.onload = async () => {
const data = getData(200, 2);
tfvis.render.scatterplot(
{ name: '训练数据' },
{
values: [
data.filter((p) => p.label === 1),
data.filter((p) => p.label === 0)
]
}
);
const model = tf.sequential();
// 增加层,让神经网络更复杂点
// 过拟合演示
model.add(
tf.layers.dense({
units: 10, // 设置更多的神经元
inputShape: [2], // 长度为2的一维数组
activation: 'tanh'
// kernelRegularizer: tf.regularizers.l2({ l2: 1 })
})
);
model.add(tf.layers.dropout({ rate: 0.9 }));
model.add(
tf.layers.dense({
units: 1,
activation: 'sigmoid'
})
);
model.compile({
loss: tf.losses.logLoss,
optimizer: tf.train.adam(0.1)
});
// 一个长度为2的一维数组
const inputs = tf.tensor(data.map((p) => [p.x, p.y]));
// 指定label,将其转换为tensor
const labels = tf.tensor(data.map((p) => p.label));
await model.fit(inputs, labels, {
validationSplit: 0.2, // 验证集分出20%
epochs: 200, //
callbacks: tfvis.show.fitCallbacks(
{ name: '训练效果' },
['loss', 'val_loss'], // 训练损失和验证的损失
{ callbacks: ['onEpochEnd'] }
)
});
};import * as tf from '@tensorflow/tfjs';
import * as tfvis from '@tensorflow/tfjs-vis';
import { getData } from './data';
window.onload = async () => {
const data = getData(200, 2);
tfvis.render.scatterplot(
{ name: '训练数据' },
{
values: [
data.filter((p) => p.label === 1),
data.filter((p) => p.label === 0)
]
}
);
const model = tf.sequential();
// 增加层,让神经网络更复杂点
// 过拟合演示
model.add(
tf.layers.dense({
units: 10, // 设置更多的神经元
inputShape: [2], // 长度为2的一维数组
activation: 'tanh'
// kernelRegularizer: tf.regularizers.l2({ l2: 1 })
})
);
model.add(tf.layers.dropout({ rate: 0.9 }));
model.add(
tf.layers.dense({
units: 1,
activation: 'sigmoid'
})
);
model.compile({
loss: tf.losses.logLoss,
optimizer: tf.train.adam(0.1)
});
// 一个长度为2的一维数组
const inputs = tf.tensor(data.map((p) => [p.x, p.y]));
// 指定label,将其转换为tensor
const labels = tf.tensor(data.map((p) => p.label));
await model.fit(inputs, labels, {
validationSplit: 0.2, // 验证集分出20%
epochs: 200, //
callbacks: tfvis.show.fitCallbacks(
{ name: '训练效果' },
['loss', 'val_loss'], // 训练损失和验证的损失
{ callbacks: ['onEpochEnd'] }
)
});
};最终效果如下:
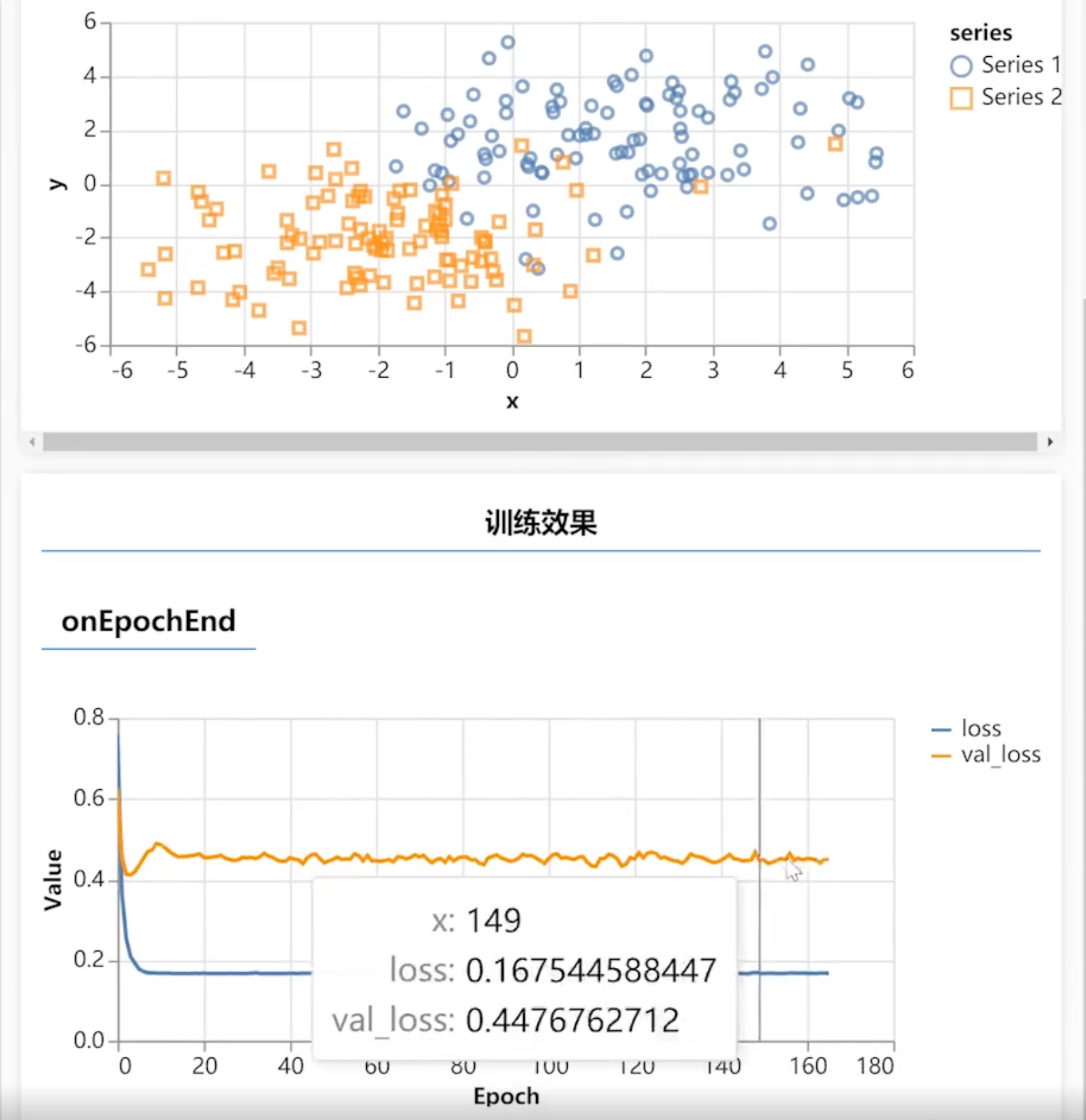
可以看到,蓝色的线,损失值已经降下去了。但是黄色的线还在不断攀升。因此,这也意味着,在这个模型已经过拟合了。
五、过拟合应对法:早停法、权重衰减、丢弃法
继续,我们刚刚了解了欠拟合和过拟合,现在来了解应对过拟合的几种方法。
1、三种法则简单介绍
- 早停法 —— 在验证级的损失曲线开始增长之前,我们就把模型的训练任务给停掉,这样就可以一定程度上的缓解过拟合。
- 权重衰减 —— 简单来说就是把权重的复杂度也作为模型损失的一部分,我们都知道训练模型就是降低模型的损失,那么既然复杂度也变成损失的一部分了,所以过于复杂的权重自然也就在训练的过程中被衰减掉了,那么这样一来就防止我们的模型过度的复杂,而导致出现过拟合现象。
- 丢弃法 —— 丢弃法则是在神经网络的隐藏层设置丢弃率,然后就会随机的丢弃某几个神经元的权重,这相当于把我们隐藏层的神经元个数变少了,间接地就相当于简化了我们的模型。那么我们的模型既然被简化了,自然就一定程度上的可以缓解过拟合了。一般来说,过拟合就是想要解决的问题很简单,但是我们的模型却太复杂,然后就出现过拟合了。
下面我们来演示下这几种方式。
2、训练过程
(1)使用早停法
如果是早停法的话,我们需要看下这个验证集损失曲线的拐点,也就是从哪个地方开始增长的。我们需要看一下那个点在哪,然后等下次在模型快要走到那个地方之前,就提早地把模型训练任务给停掉即可。
(2)使用权重衰减
这种方法将会把过度复杂的权重给衰减掉,在tensorflow里面,通过kernelRegularizer来设置。如下代码所示:
window.onload = async () => {
model.add(
tf.layers.dense({
units: 10,
inputShape: [2],
activation: 'tanh'
kernelRegularizer: tf.regularizers.l2({ l2: 1 }) // 权重衰减,L2正则化
})
);
};window.onload = async () => {
model.add(
tf.layers.dense({
units: 10,
inputShape: [2],
activation: 'tanh'
kernelRegularizer: tf.regularizers.l2({ l2: 1 }) // 权重衰减,L2正则化
})
);
};来看下效果:
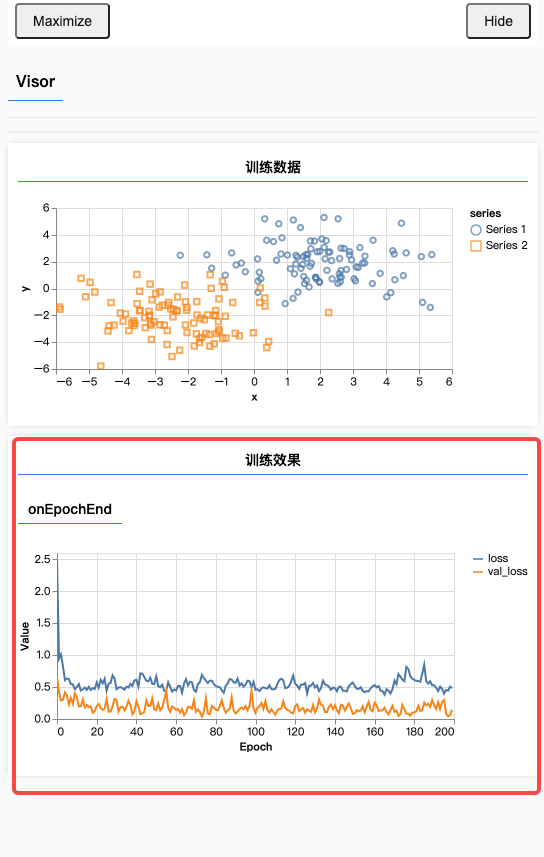
可以看到,黄色线的损失给降下来了。
(3)丢弃法
我们在这个最复杂的隐藏层后面再加一层,来设置丢弃率。代码如下所示:
window.onload = async () => {
……
// 会雨露均沾地随机选择9个
model.add(tf.layers.dropout({ rate: 0.9 })); // 丢弃率,丢弃一部分神经元的权重
……
};window.onload = async () => {
……
// 会雨露均沾地随机选择9个
model.add(tf.layers.dropout({ rate: 0.9 })); // 丢弃率,丢弃一部分神经元的权重
……
};验证效果如下:
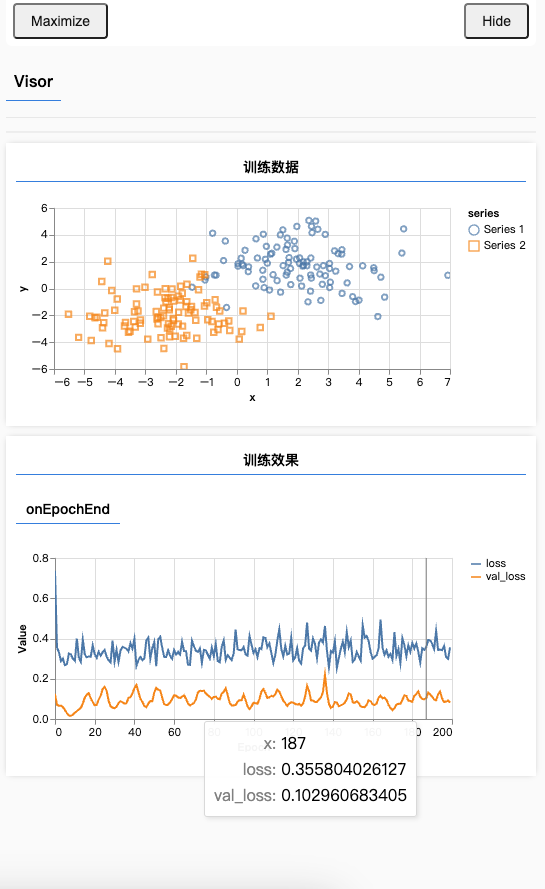
可以看到,黄色的线压下去了。但颜色的线为什么反而会高了呢?这是因为我们的模型太简单了,然后我们的数据集有带有噪音,所以会导致它高了。