前言
在上一篇文章中我们了解到,结构化系统分析得到系统的逻辑模型,解决软件“做什么”的问题。而在我们接下来的这篇文章中,将讲解结构化系统设计,那么结构化系统设计可以做什么呢?结构化系统设计是为了得到目标系统的物理模型,解决软件“怎么做”的问题。先用一张图来了解从逻辑模型到物理模型的过渡。
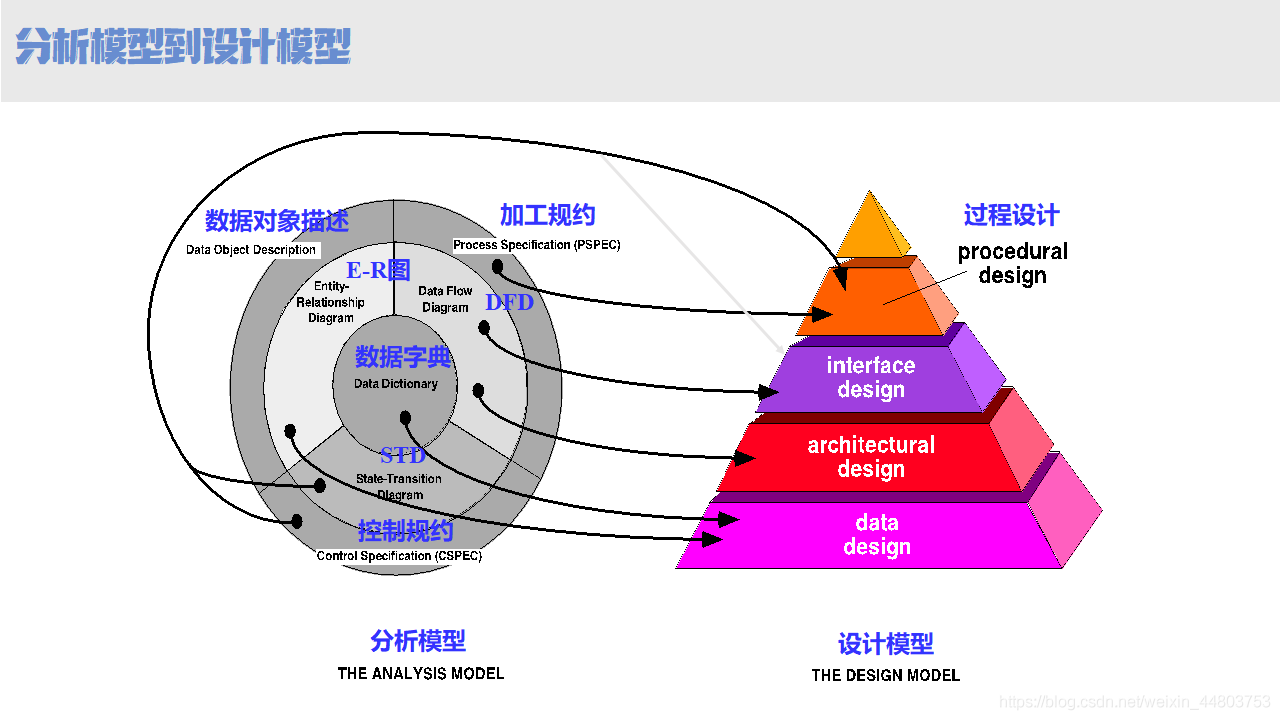
了解完之后,我们来开始讲解结构化系统设计。
一、设计的目标和任务
1、目标
得到目标系统的物理模型 —— 解决软件”怎么做“问题。📝
2、任务
结构化系统设计中的任务,指使用信息域来表示的软件需求、功能和性能需求,进行:
- 数据设计——侧重于数据结构的定义。
- 系统结构设计——定义软件系统各主要成份之间的关系。
- 接口设计——描述了软件内部、软件和协作系统之间以及软件和人之间如何通信。
- 过程设计——把结构成份地转换成软件的过程性描述,且在编码阶段,根据这种过程性描述,生成源程序代码,然后通过测试最终得到完整有效的软件。
了解完软件设计的目标和任务,相信大家对其有了一个基本的了解。我们再来看看这四个任务在开发阶段的信息流向。
3、开发阶段的信息流
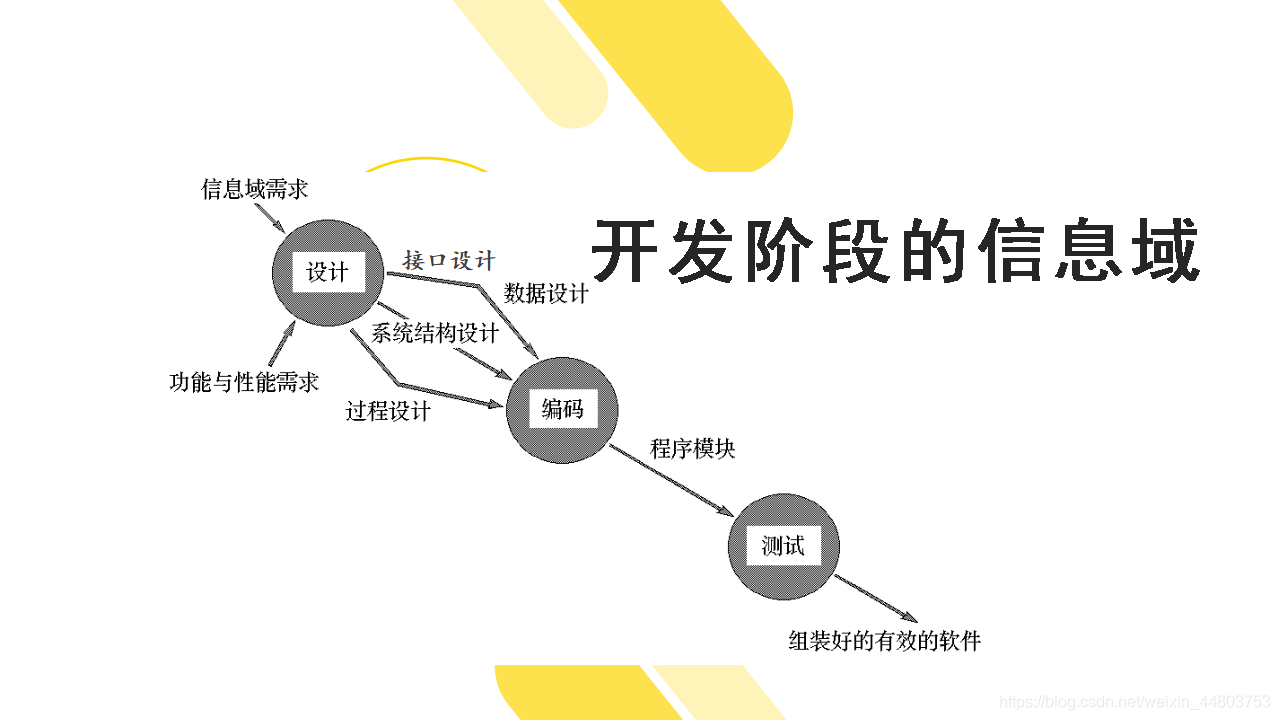
从上图可知,从设计到编码阶段,软件要经过数据设计、系统结构设计、接口设计和过程设计。
4、软件设计的重要性
所以,软件设计是后续开发步骤和软件维护工作的基础。如果一个软件没有设计,那么会整个系统结构将会是非常不稳定的。
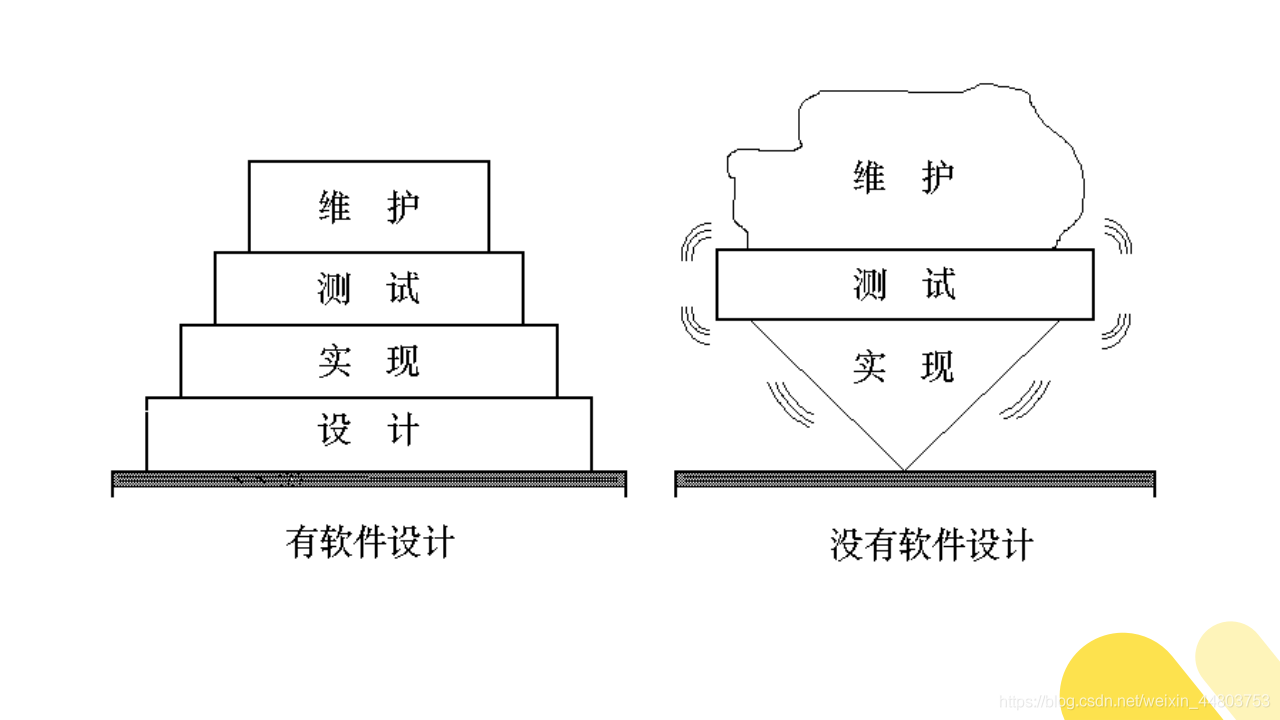
大家可以看到,左图是一个有经过软件设计的系统,看起来条理相对清晰,系统相对稳固一点。而右图是一个没有经过软件设计的系统,像冰淇淋似的摇摇晃晃的,很是不稳固。所以,对于一个软件来说,软件设计是非常重要的。
5、软件设计的技术观点和管理观点
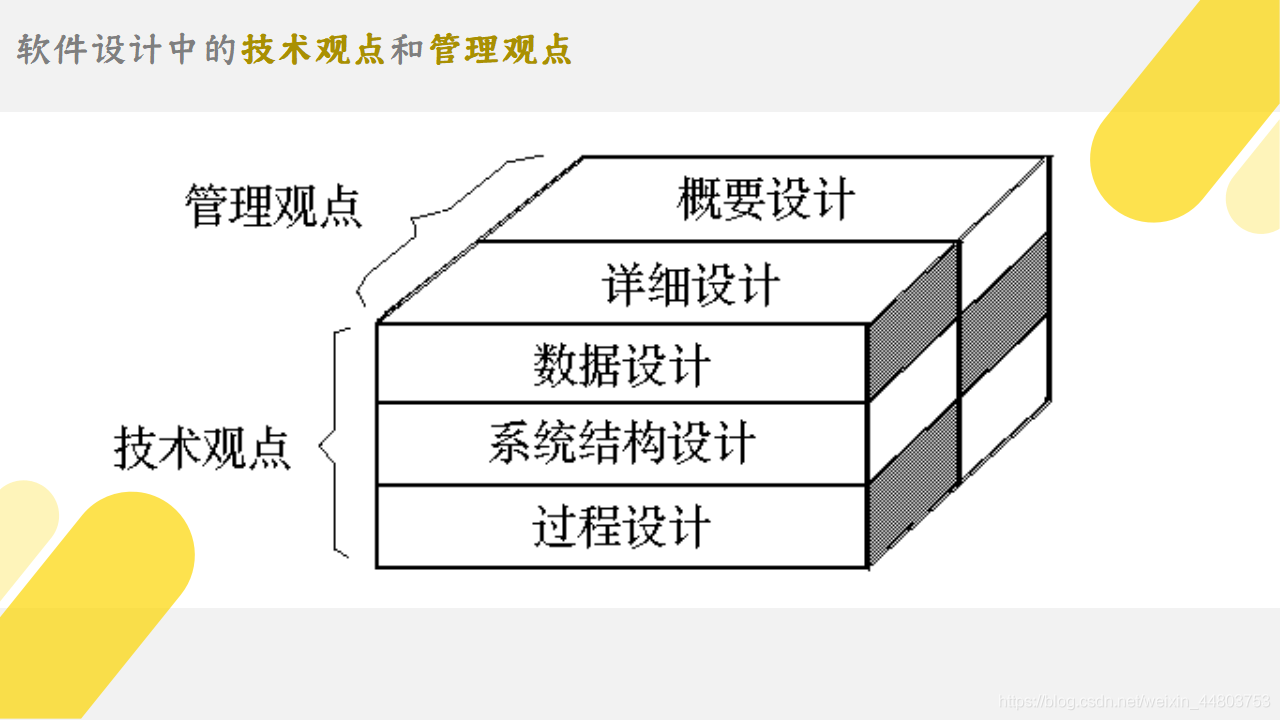
从上图中可以看到,在一个软件中,从管理层面来看,管理层的人一般负责概要设计和详细设计。而从技术层面来看,技术人员主要负责数据设计、系统结构设计、接口设计和过程设计。
二、设计基础
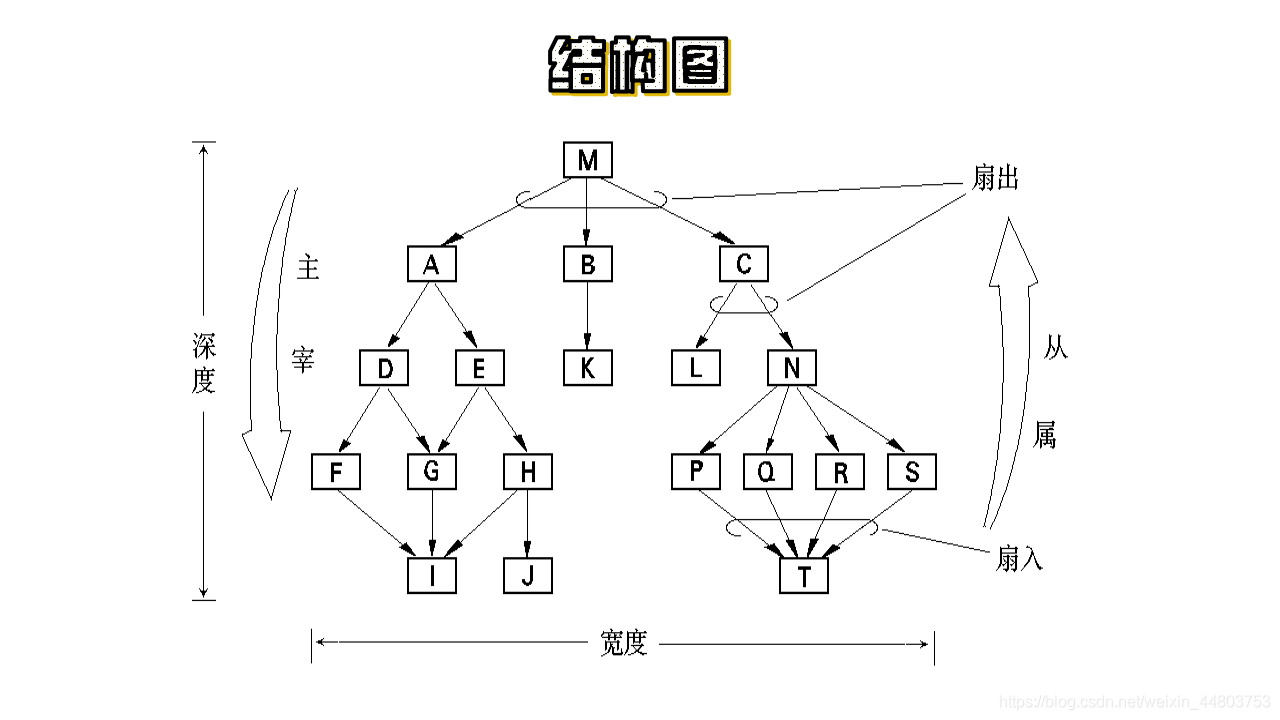
1、结构图(体系结构图、模块结构图)
结构图反映模块之间的层次调用关系和联系:它以特定的符号表示模块、模块间的调用关系和模块间信息的传递。
(1)分析结构图三者间的关系
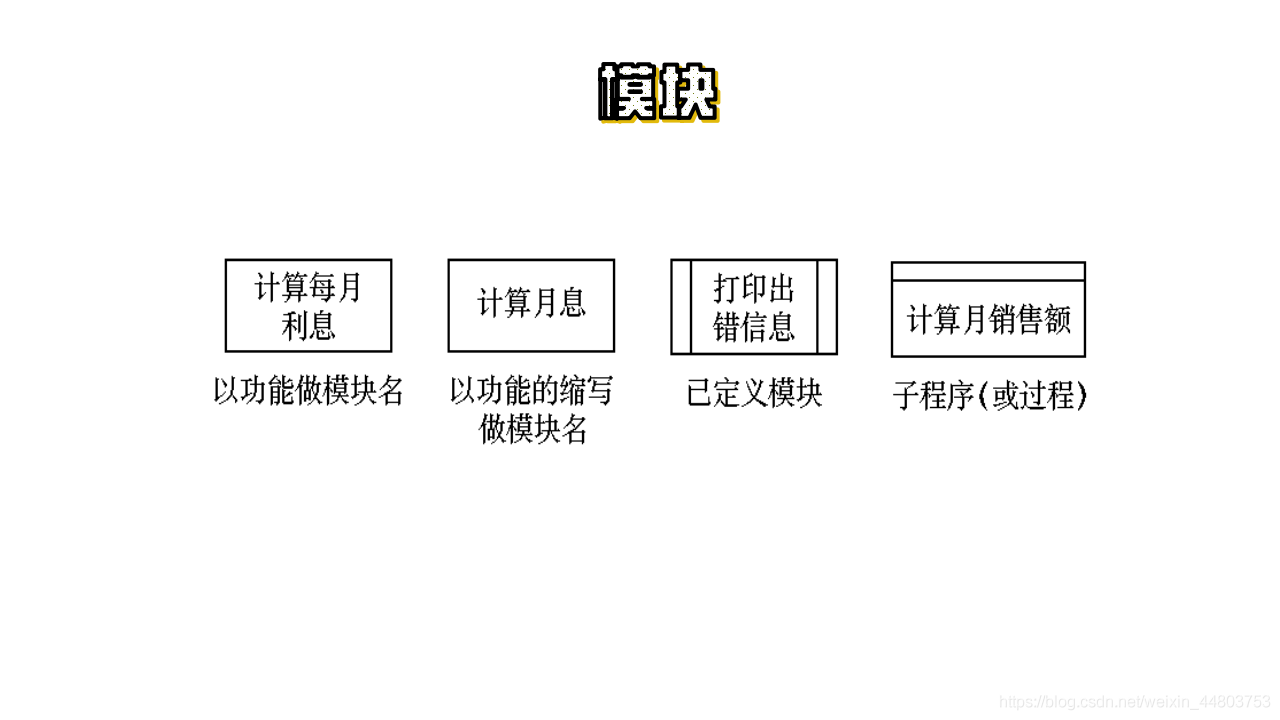
1)模块: 模块用矩形框表示,并用模块的名字标记它。
如图所示:
2)模块间的调用关系: 模块之间用单向箭头连接,箭头从调用模块指向被调用模块。
如图所示:
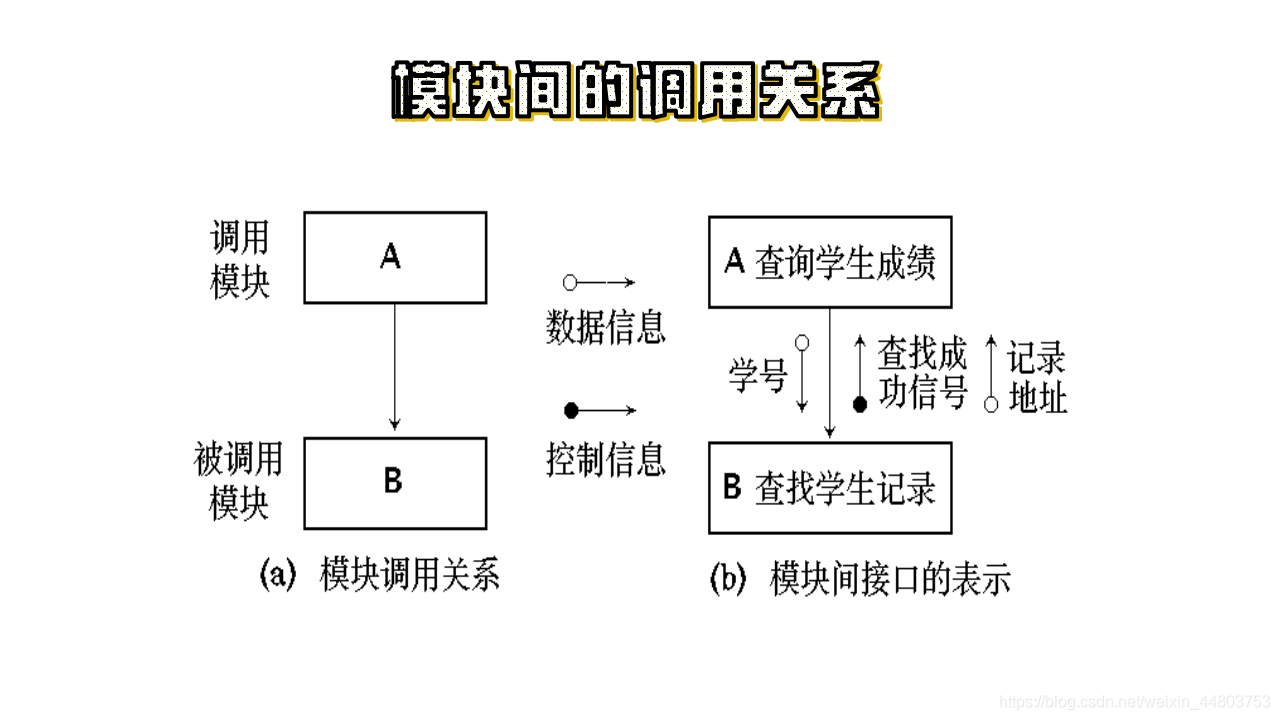
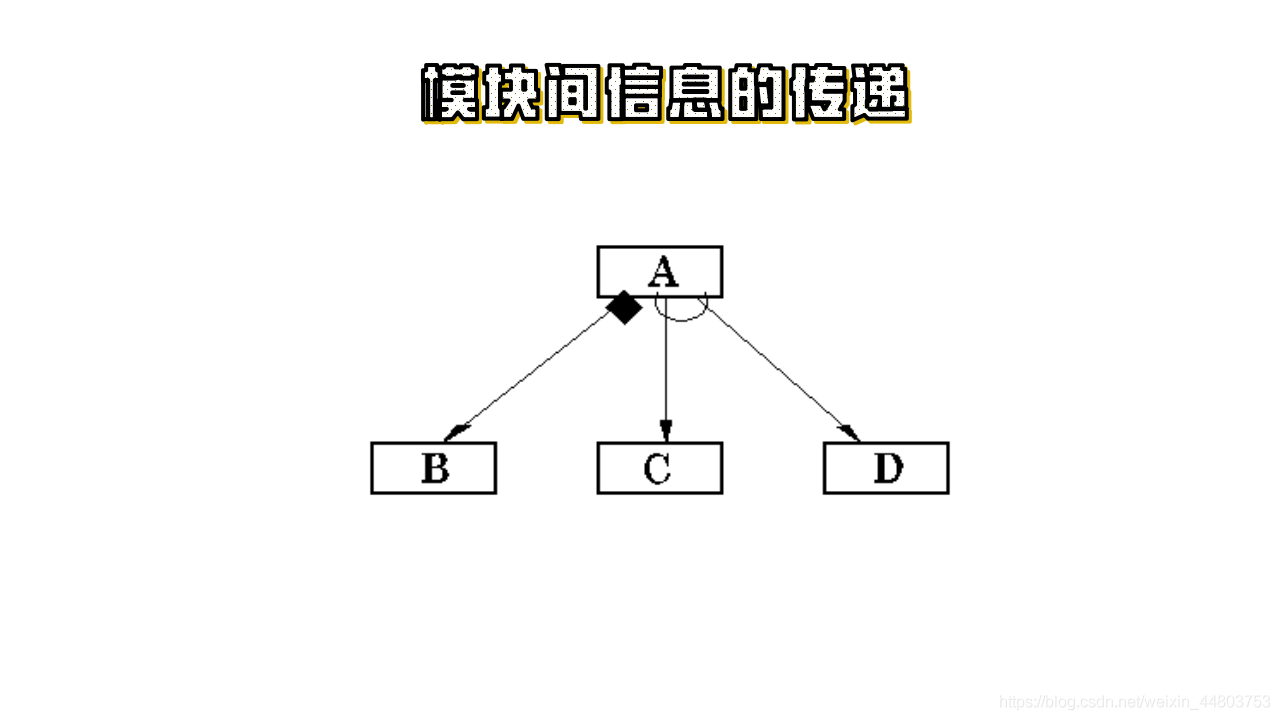
3)模块间信息的传递: 当一个模块调用另一个模块时,调用模块把数据或控制信息传送给被调用模块,以使得被调用模块能够运行。而被调用模块在执行过程中又把它产生的数据或控制信息回送给调用模块。
如图所示:
下图所表示的是,在模块 A 的箭头尾部有一个菱形符号,表示 模块 A 有条件地调用另一个 模块 B 。如果一个箭头尾部以一个弧形符号表示,表示反复调用。如下图所示, 模块A 反复调用 模块C 和 模块D 。
(2)结构图图例
结合模块、模块间的调用信息、模块间信息的传递三者,生成一张完成的结构图。如下图所示:
2、模块化(思想)
(1)模块化是什么: 指把一个大的系统划分成若干个小模块(东西),即被称为模块化。
(2)模块化想要达到的目的: 使复杂问题简单化处理。
3、抽象化(“开门”)
(1)抽象化是什么
- 软件系统进行模块设计时,可以有不同的抽象层次。
- 在最高的抽象层次上,可以使用问题所处环境的语言概括地描述问题的解法。
- 在较低的抽象层次上,则采用过程化的方法。
(2)抽象化的类型
1)过程抽象(开)
从系统定义到实现,每进展一步都可以看做是对软件解决方法的抽象化过程的一次细化。
比如:
- 在软件需求分析阶段,用“问题所处环境中大家所熟悉的术语”来描述软件的解决方法。
- 在从概要设计到详细设计的过程中,抽象化的层次逐次降低。当产生源程序时到达最低抽象层次。
2)数据抽象(门)
在不同层次上描述数据对象的细节,定义与该数据对象相关的操作。
(3)抽象化举例
1)过程抽象
Question: 开发一个 CAD 软件的三层抽象。
Answer:
抽象层次 Ⅰ: 用问题所处环境的术语来描述这个软件:
该软件包括一个计算机绘图界面,向绘图员显示图形,以及一个数字化仪界面,用以代替绘图板和丁字尺。所有直线、折线、矩形、圆及曲线的描画、所有的几何计算、所有的剖面图和辅助视图都可以用这个 CAD 软件实现……
抽象层次 Ⅱ: 任务需求的描述。
CAD SOFTWARE TASKS
user interaction task;
2-D drawing creation task;
graphics display task;
drawing file management task;
end.CAD SOFTWARE TASKS
user interaction task;
2-D drawing creation task;
graphics display task;
drawing file management task;
end.在这个抽象层次上,未给出“怎样做”的信息,不能直接实现。
抽象层次 Ⅲ: 程序过程表示。
以 2-D (二维)绘图生成任务为例:
PROCEDURE:2-D drawing creation
REPEAT UNTIL (drawing creation task terminates)
DO WHILE (digitizer interaction occurs)
digitizer interface task;
DETERMINE drawing request CASE;
line:line drawing task;
rectangle:rectangle drawing task;
circle:circle drawing task;
……PROCEDURE:2-D drawing creation
REPEAT UNTIL (drawing creation task terminates)
DO WHILE (digitizer interaction occurs)
digitizer interface task;
DETERMINE drawing request CASE;
line:line drawing task;
rectangle:rectangle drawing task;
circle:circle drawing task;
……2)数据抽象
Question: 在 CAD 软件中,定义一个叫做 drawing 的数据对象。
Answer:
可将 drawing 规定为一个抽象数据类型,定义它的内部细节为:
TYPE drawing IS STRUCTURE
DEFIND number IS STRING LENGTH(12);
geometry DEFIND ……
notes IS STRING LENGTH(256);
BOM DEFIND
END drawing TYPE;TYPE drawing IS STRUCTURE
DEFIND number IS STRING LENGTH(12);
geometry DEFIND ……
notes IS STRING LENGTH(256);
BOM DEFIND
END drawing TYPE;数据抽象 drawing 本身由另外一些数据抽象,如 geometry 、 BOM (bill of materials) 构成。
定义 drawing 的抽象数据类型之后,可引用它来定义其它数据对象,而不必涉及 drawing 的内部细节。
例如,定义:blue-print IS INSTANCE OF drawing 或 schematic IS INSTANCE OF drawing。
4、信息隐藏
信息隐蔽,于 1972 年由 D.Parnas 提出,是最早的软件开发方法。信息隐蔽指的是每个模块的实现细节对于其它模块来说是隐蔽的。也就是说,模块中所包含的信息(包括数据和过程)不允许其它不需要这些信息的模块使用。
三、模块的独立性
1、模块
(1)属性
“模块”,又称为“组件”,它一般具有如下三个基本属性:
- 功能: 描述该模块实现什么功能。
- 逻辑: 描述模块内部怎么做。
- 状态: 描述该模块使用时的环境和条件。
(2)特性
- 外部特性: 模块的模块名、参数表、参数表其中的输入参数和输出参数,以及对程序和整个系统所造成的影响。
- 内部特性: 完成其功能的程序代码和仅提供给该模块内部使用的数据,即程序和数据。
2、模块的独立性
(1)模块的独立性是什么
模块独立性,是指软件系统中每个模块只涉及软件要求的具体子功能,且和软件系统中其它模块相对应的接口是简单的。
例如: 若一个模块只具有单一的功能且与其它模块没有太多的联系,则称此模块具有模块独立性。
(2)两个准则
一般采用两个准则来度量模块的独立性。即模块间耦合和模块内聚。如以下两点:
- 耦合是模块之间的互相连接的紧密程度的度量。
- 内聚是模块内各功能部分之间的度量。
注意:独立性强的模块,说明这个模块高内聚、低耦合。
(3)模块独立性的 14 字经
14 字经 $\begin{cases} 耦合:七字经 —— 非数标控外公内,耦合度越高,独立性越低 \ 内聚:七字经 —— 功信通过时逻巧,内聚度越低,独立性越低 \ \end{cases}$
下面围绕七种耦合类型和七种内聚类型进行讲解。
3、耦合的七种类型
模块间的耦合主要包含以下七种类型。

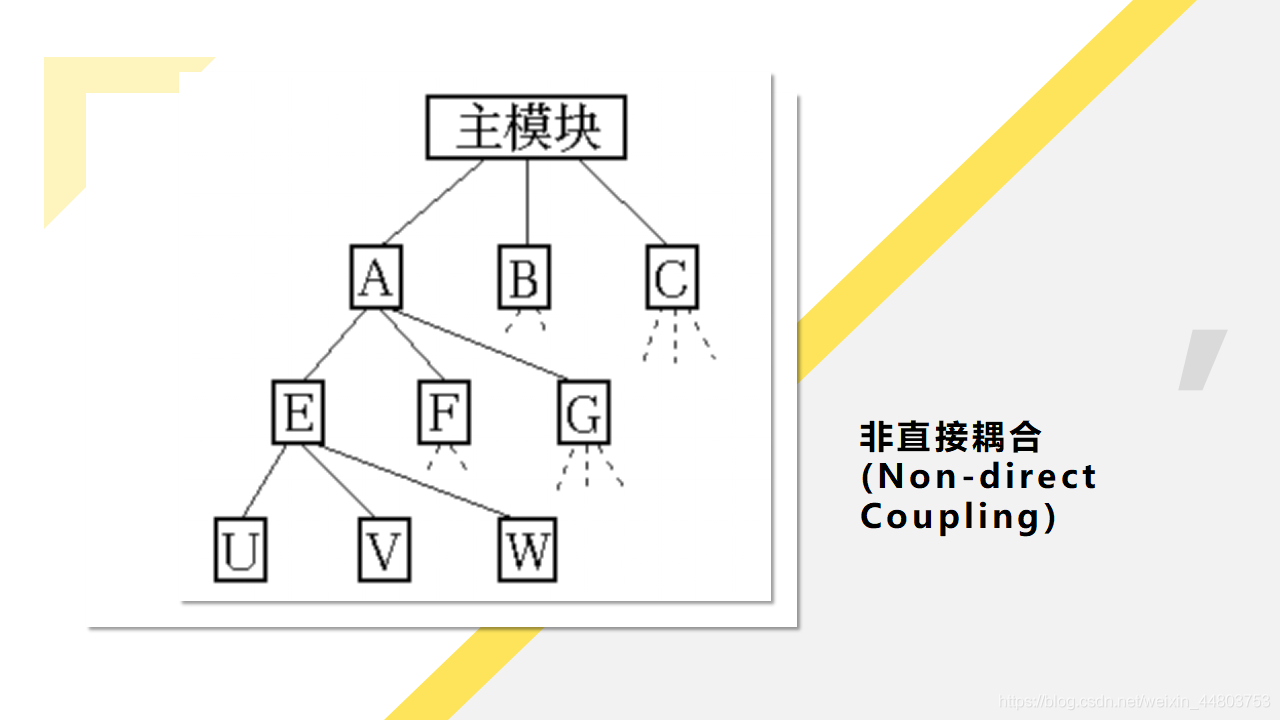
(1)非直接耦合(Non-direct Coupling)
两个模块之间没有直接关系,它们之间的联系完全是通过主模块的控制和调用来实现的。非直接耦合的模块独立性最强。
如下图所示:
(2)数据耦合
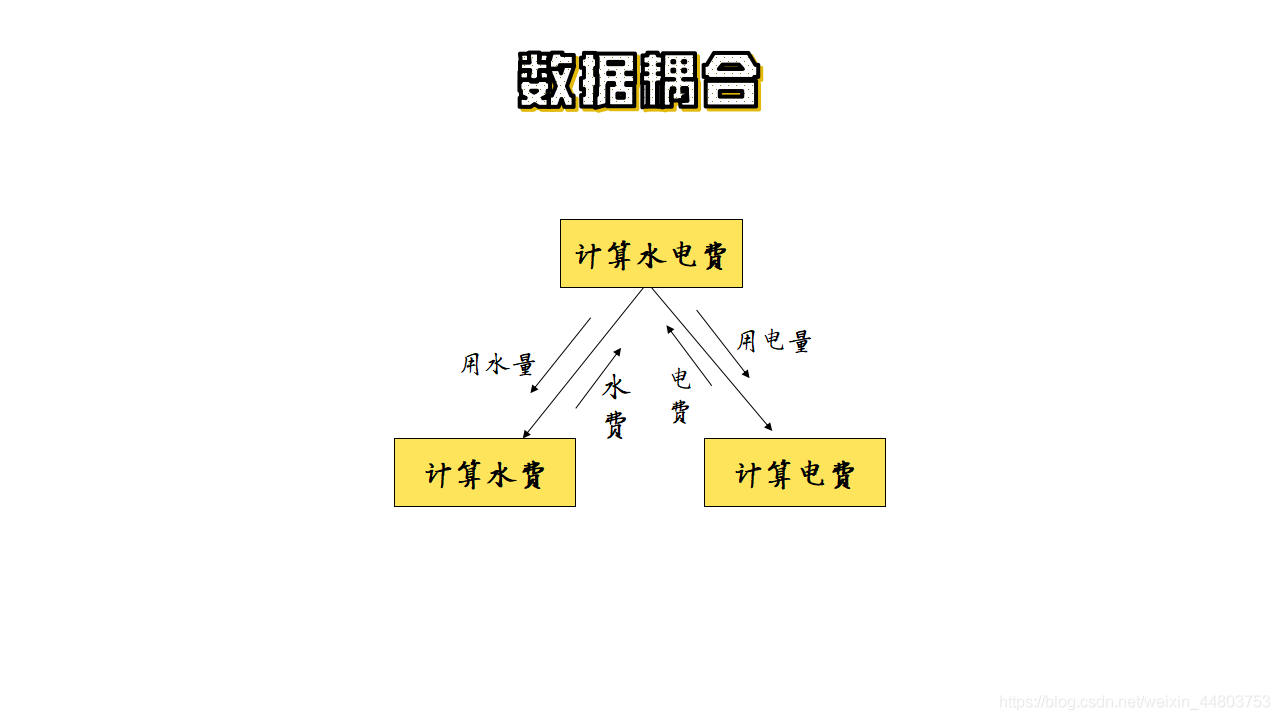
一个模块访问另一个模块时,彼此之间是通过简单数据参数(不是控制参数、公共数据结构或外部变量)来交换输入、输出信息的。
如下图所示:
(3)标记耦合
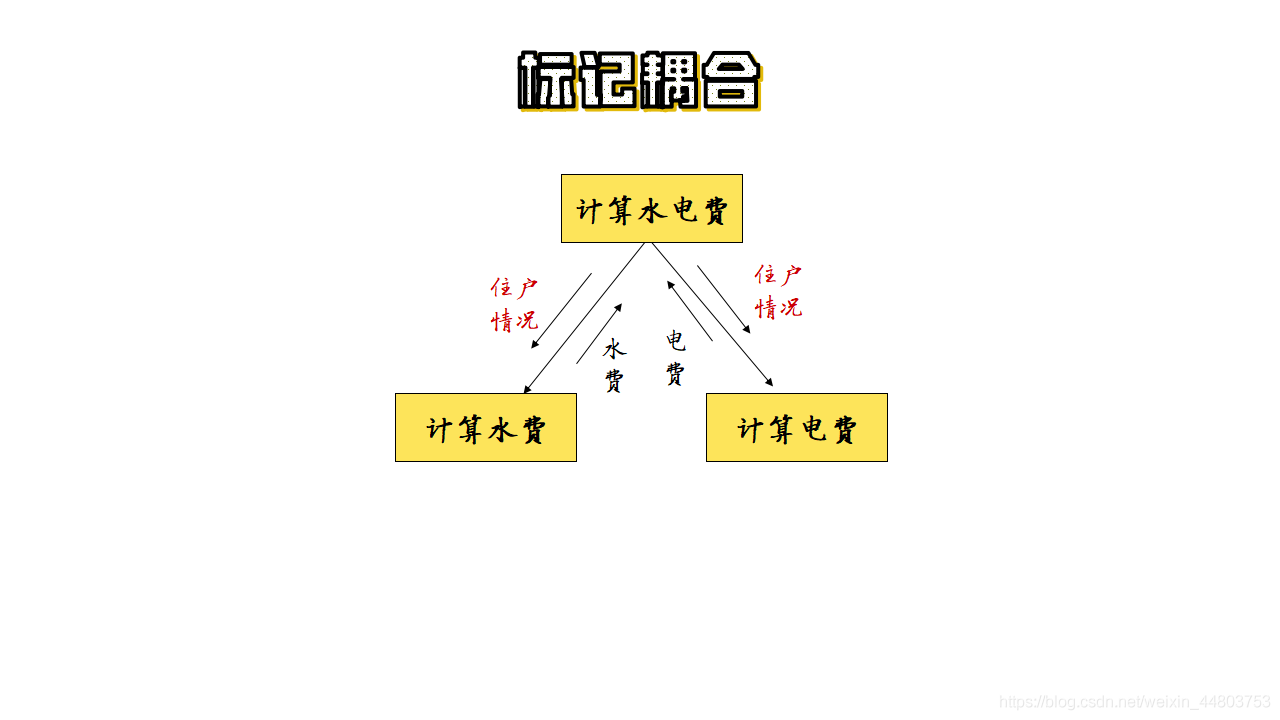
一组模块通过参数表来传递记录信息,就是标记耦合。这个记录是某一数据结构的子结构,而不是简单变量。
如下图所示:
(4)控制耦合
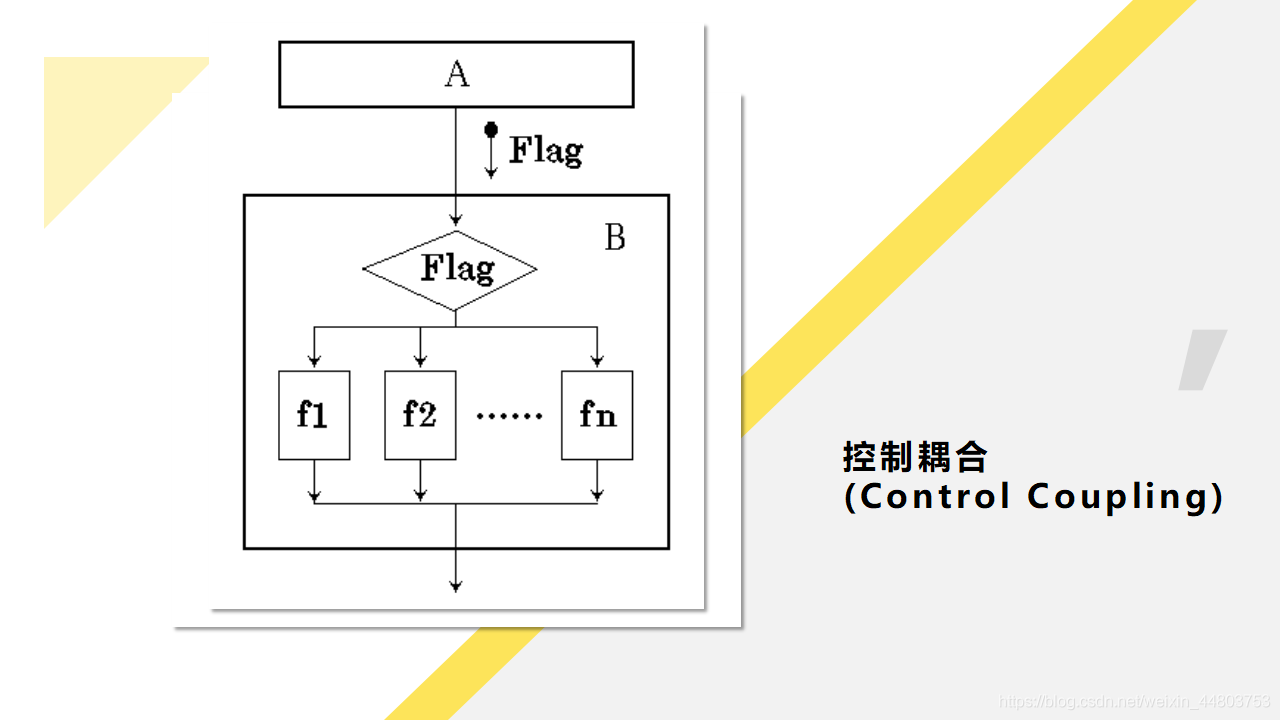
如果一个模块通过传送开关、标志、名字等控制信息,明显地控制和选择另一模块的功能,就是控制耦合。
如下图所示:
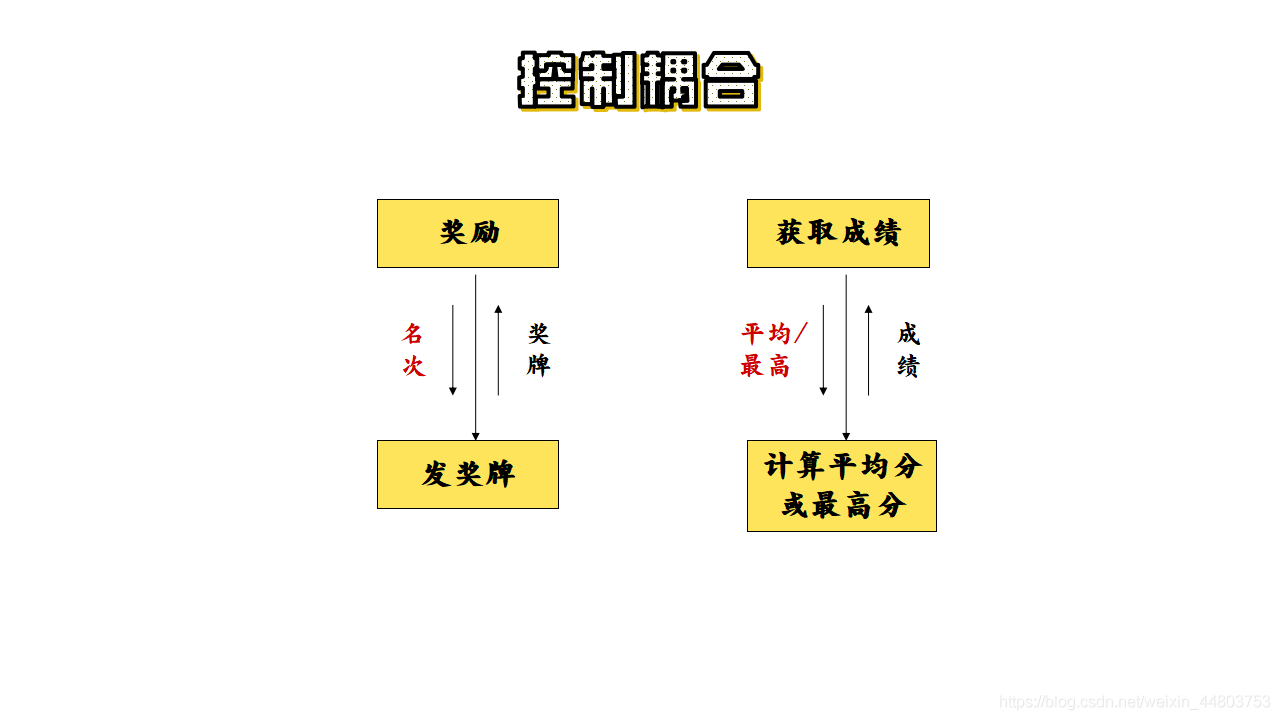
(5)外部耦合
一组模块都访问同一个全局简单变量而不是同一全局数据结构,同时不是通过参数表传递该全局变量的信息,则称之为外部耦合。
(6)公共耦合
若一组模块都访问同一个公共数据环境,则它们之间的耦合就称为公共耦合。公共的数据环境可以是全局数据结构、共享的通信区、内存的公共覆盖区等。
公共耦合的复杂程度随耦合模块的个数增加而显著增加。若只是两模块间有公共数据环境,则公共耦合有两种情况,分别是松散公共耦合和紧密公共耦合。
如下图所示:
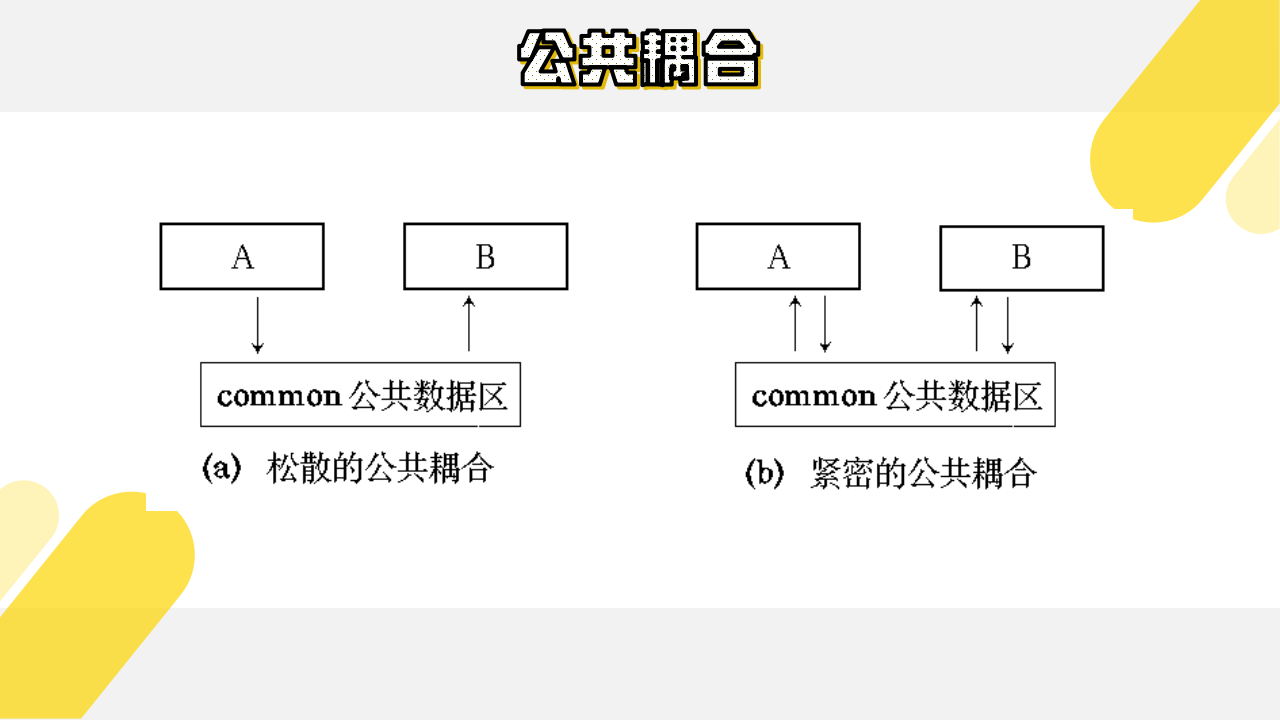
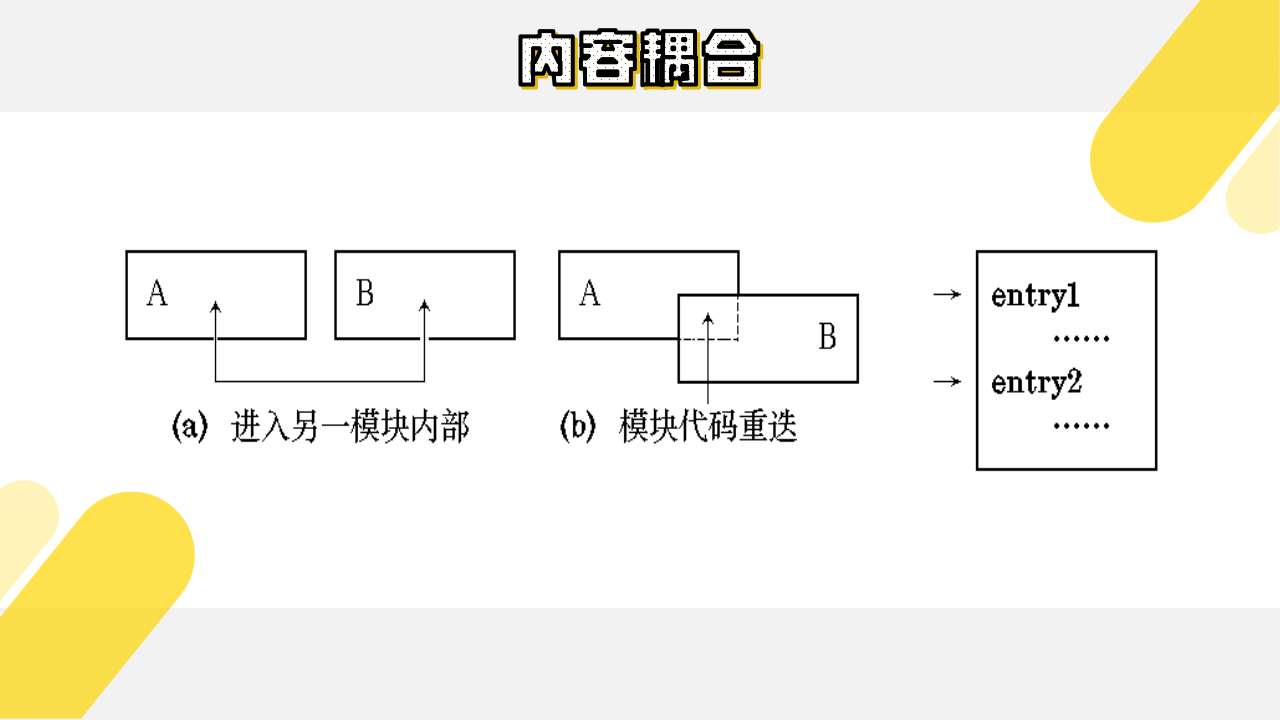
(7)内容耦合
如果发生下列情形,即表示两个模块之间发生了内容耦合:
(1) 一个模块直接访问另一个模块的内部数据。
(2)一个模块不通过正常入口转到另一模块内部。
(3)两个模块有一部分程序代码重迭。
(4)一个模块有多个入口。
注: 满足以上其中一个条件即算内容耦合。
如下图所示:
了解完以上其模块间的耦合后,我们对以下四种耦合方式进行一个归纳总结。
| 模块间耦合形式 | 可读性 | 错误扩散能力 | 可修改性 | 通用性 |
|---|---|---|---|---|
| 数据耦合 | 好 | 弱 | 好 | 好 |
| 控制耦合 | 中 | 中 | 中 | 中 |
| 公共耦合 | 不好 | 强 | 不好 | 交差 |
| 内容耦合 | 最差 | 最强 | 最差 | 差 |
4、内聚的七种类型
模块内各功能部分之间的内聚主要包含以下七种类型。

(1)功能内聚
一个模块中的各个部分都是完成某一项具体功能时必不可少的组成部分,或者说该模块中所有部分都是为了完成一项具体功能而协同工作,紧密联系,不可分割的,则称该模块为功能内聚模块。
(2)信息内聚
这种模块完成多个功能,各个功能都在同一个数据结构上操作,每一项功能有一个唯一的入口点。这个模块将根据不同的要求,确定该执行哪一个功能。由于这个模块的所有功能都是基于同一个数据结构(符号表),因此,它是一个信息内聚的模块。
如下图所示:
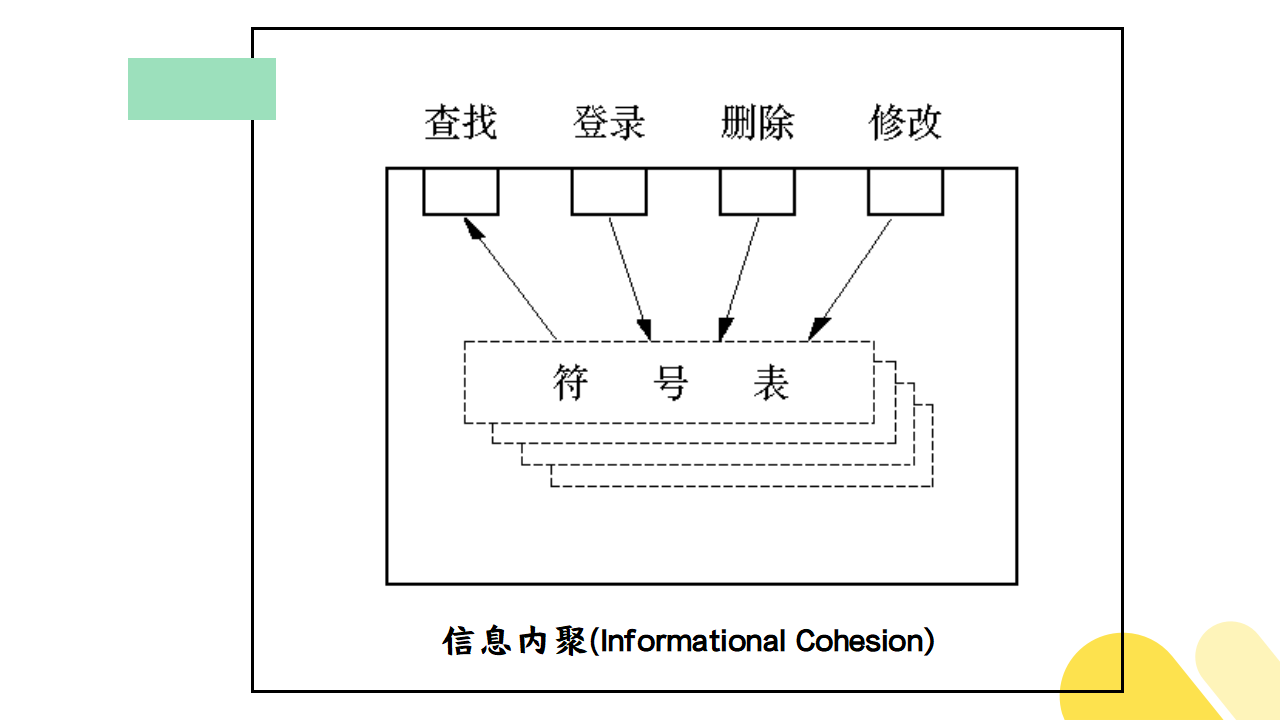
信息内聚模块可以看成是多个功能内聚模块的组合,并且达到信息的隐蔽。即把某个数据结构、资源或设备隐蔽在一个模块内,不被别的模块所知晓。
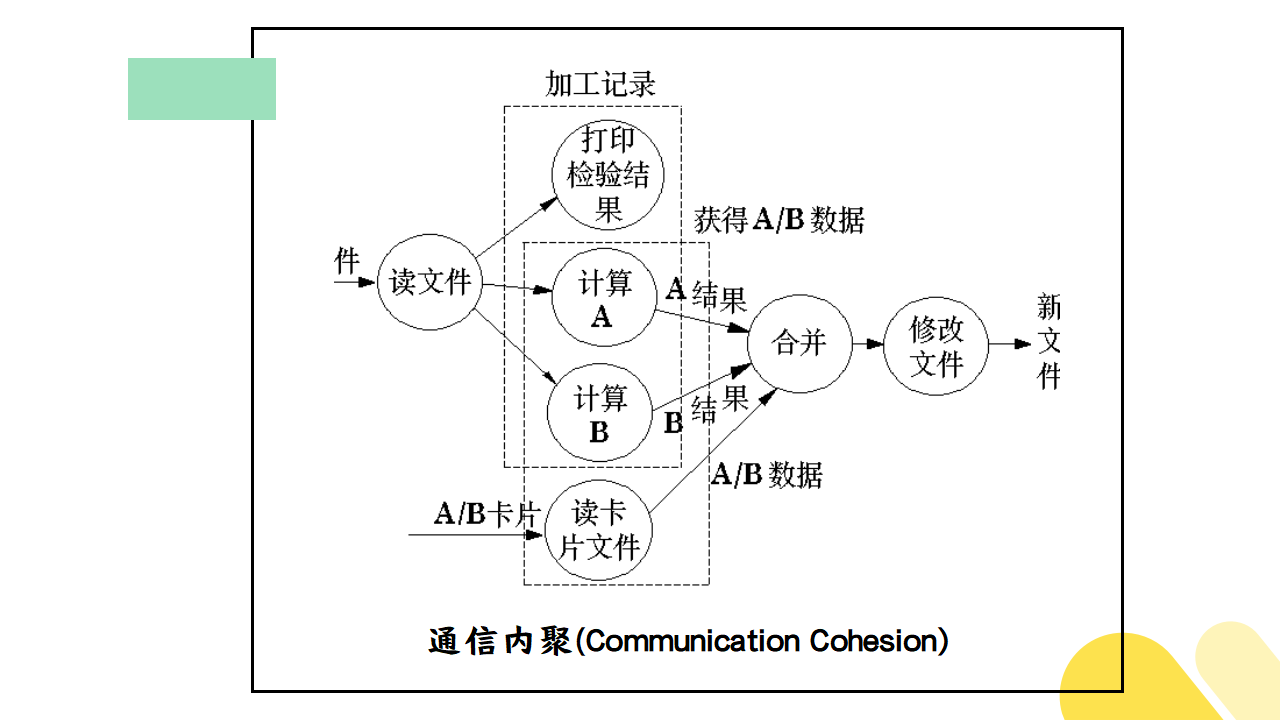
(3)通信内聚
如果一个模块内各功能部分都使用了相同的输入数据,或产生了相同的输出数据,则称之为通信内聚模块。通常,通信内聚模块是通过数据流图来定义的。
如下图所示:
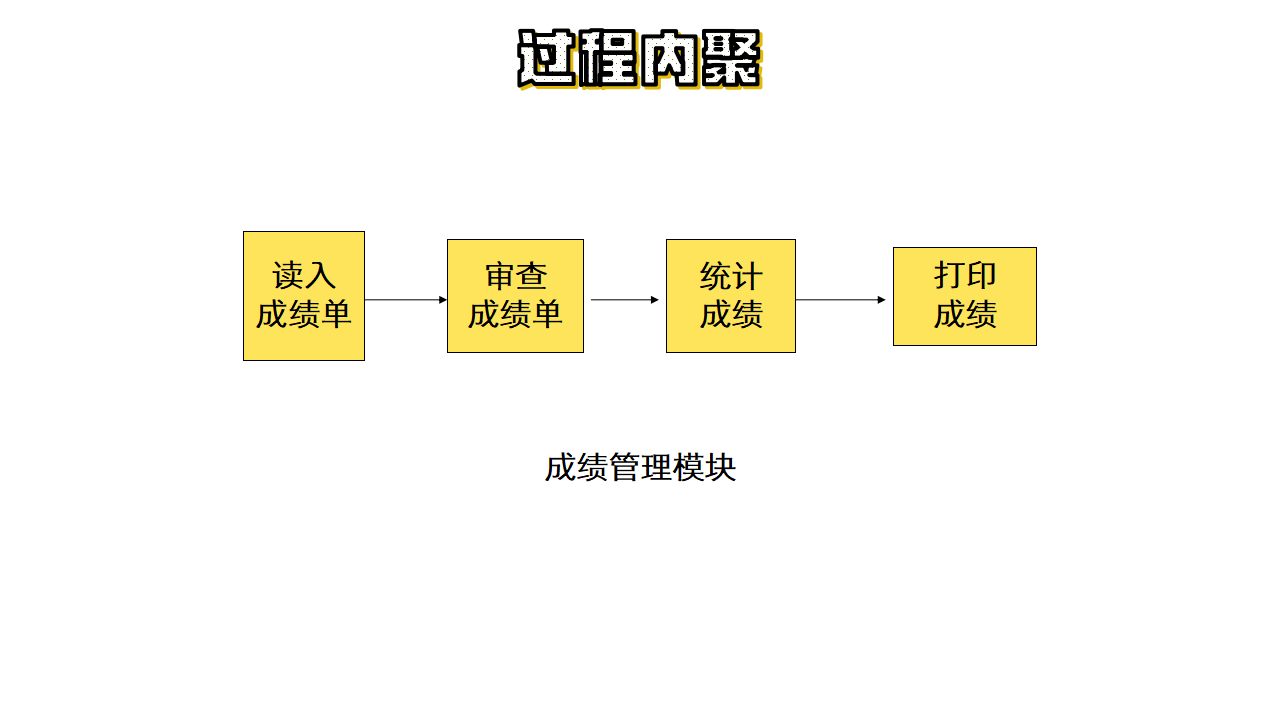
(4)过程内聚
使用流程图作为工具设计程序时,把流程图中的某一部分划分出组成模块,就得到了过程内聚模块。例如,把流程图中的循环部分、判定部分、计算部分分成三个模块,这三个模块都是过程内聚模块。所有的处理元素必须按按照指定顺序来执行。
如下图所示:
(5)时间内聚
时间内聚又称为经典内聚。这种模块大多数为多功能模块,但模块中各个功能的执行与时间有关,通常要求所有功能必须在同一时间段内执行。例如初始化模块和终止模块。
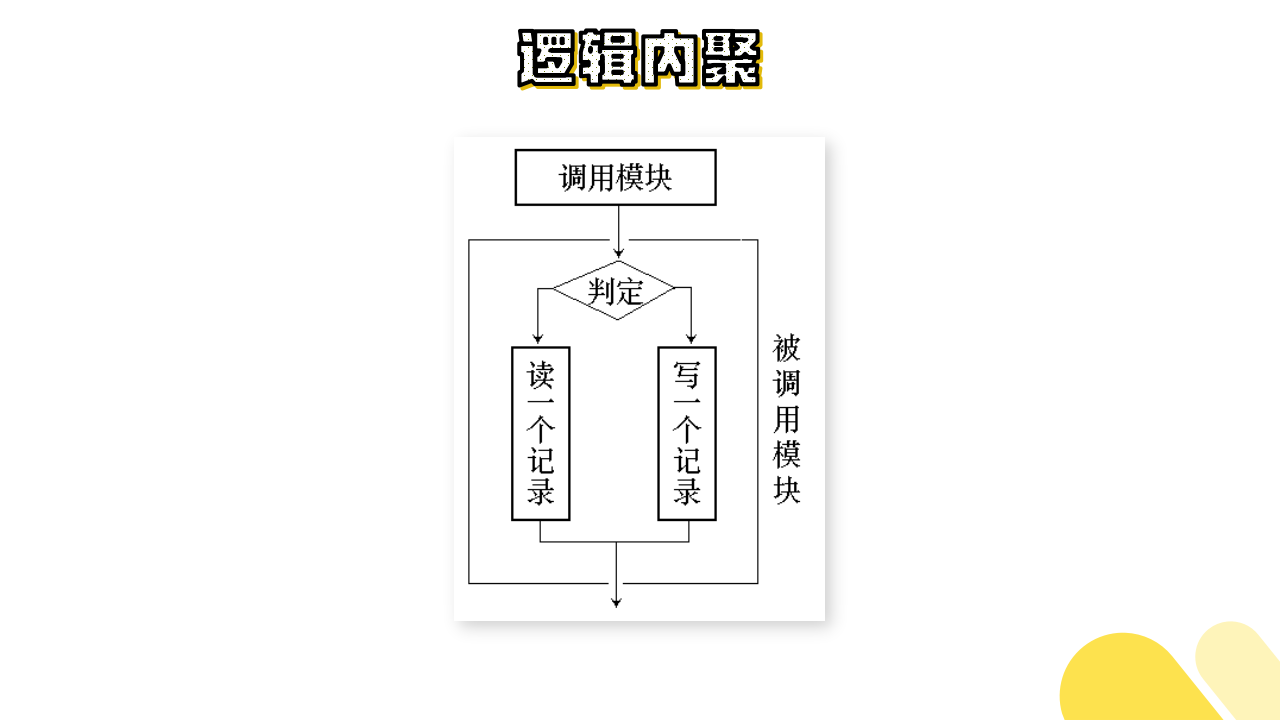
(6)逻辑内聚
这种模块把几种相关的功能组合在一起,每次被调用时,由传送给模块的判定参数来确定该模块应执行哪一种功能。
如下图所示:
(7)巧合内聚
巧合内聚,也称为偶然内聚。指当模块内各部分之间没有联系,或者即使有联系,这种联系也很松散,则称这种模块为巧合内聚模块,它是内聚程度最低的模块。
了解完以上模块内各功能部分之间的内聚后,我们对这七种内聚方式进行一个归纳总结。
| 内聚形式 | 连接形式 | 可修改性 | 可读性 | 通用性 | 联系程度 |
|---|---|---|---|---|---|
| 功能内聚 | 好 | 好 | 好 | 好 | 高 |
| 信息内聚 | 好 | 好 | 好 | 中 | ↑ |
| 通信内聚 | 中 | 中 | 中 | 不好 | ↑ |
| 过程内聚 | 中 | 中 | 中 | 不好 | ↑ |
| 时间内聚 | 不好 | 不好 | 中 | 最坏 | ↑ |
| 逻辑内聚 | 最坏 | 最坏 | 不好 | 最坏 | ↑ |
| 偶然内聚 | 最坏 | 最坏 | 最坏 | 最坏 | 低 |
四、软件的体系结构设计
1、体系结构风格
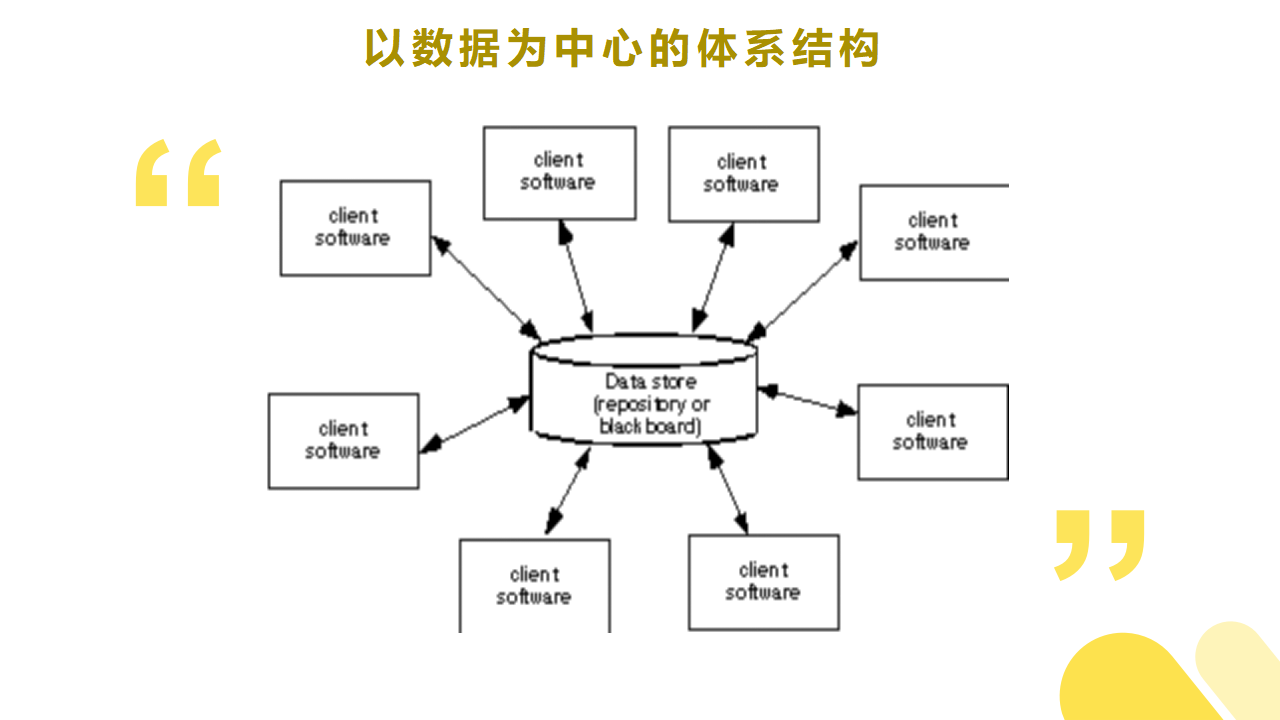
(1)以数据为中心的体系结构
以数据为中心的体系结构风格是一种共享数据源的信息传递方式,例如:典型应用、搜索引擎。
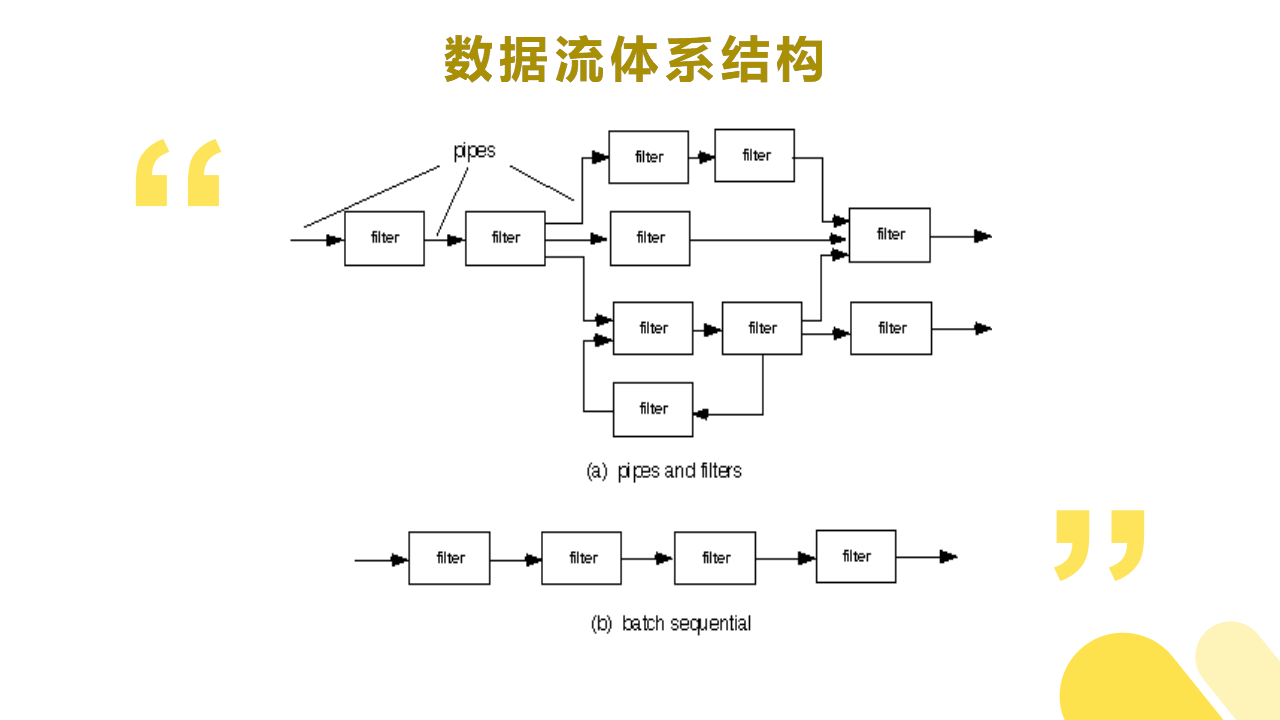
(2)数据流体系结构
1)构造子: filter ;
2)连接子: pipe ;
3)特点:
- 设计者能够理解整个系统对输入输出的影响,输入输出是过滤器的组成部分。
- 任意两个过滤器可以连接在一起,它们可以很容易地应用于其它系统。
- 系统发展演变很容易进行,因为新的过滤器可以很容易地加进来,而旧的过滤器也可以很容易地删减下去。
- 由于过滤器的独立性,设计者可以模拟系统行为和分析系统特性,比如吞吐量。
- 允许过滤器的并行执行。
4)缺点:
- 使用批量处理,不适合处理交互的应用程序。
- 当两个数据流是相关的时候,系统必须维护它们之间的对应关系。
- 过滤器的独立性意味着一些过滤器必须要复制一些由其他过滤器完成的准备功能,这样会影响性能,并使代码变得十分复杂。
5)图例
(3)调用和返回体系结构
1)特点:
- 设计模型是事件驱动的,基于广播的概念。它不同于直接调用一个过程,而是由一个组件宣布一个或多个事件要发生了。然后,其他组件将一个过程与这些事件联系起来(称为程序注册),再由系统调用这些注册程序。
- 数据交换是通过储存库中的共享数据完成的。
2)适用范围:
- 经常用于分组交换网络中或是基于活动者的系统中。
- 用于保持数据库中的一致性。
- 用于用户界面中以便分开数据和管理数据的应用程序。
3)优点:
- 对复用其它系统的组件特别有用。
4)缺点:
- 不能保证某个组件会响应一个事件。
- 测试和检查正确性很困难。
(4)面向对象体系结构
1)构造子: objects 、classes ;
2)连接子: methods ;
3)特点:
- 一个对象必须保持数据类型的完整性,还有就是数据表示对于其他对象是隐藏的。
- 与管道-过滤器系统不同的是,一个对象必须知道其他对象特征,以便于它们之间进行交互,而过滤器是完全独立的。对象间的这种依赖意味着一个对象的改变将影响到调用该对象的组件。
(5)层次式体系结构
1)构造子: 过程、集合;
2)连接子: 调用;
3)图例:
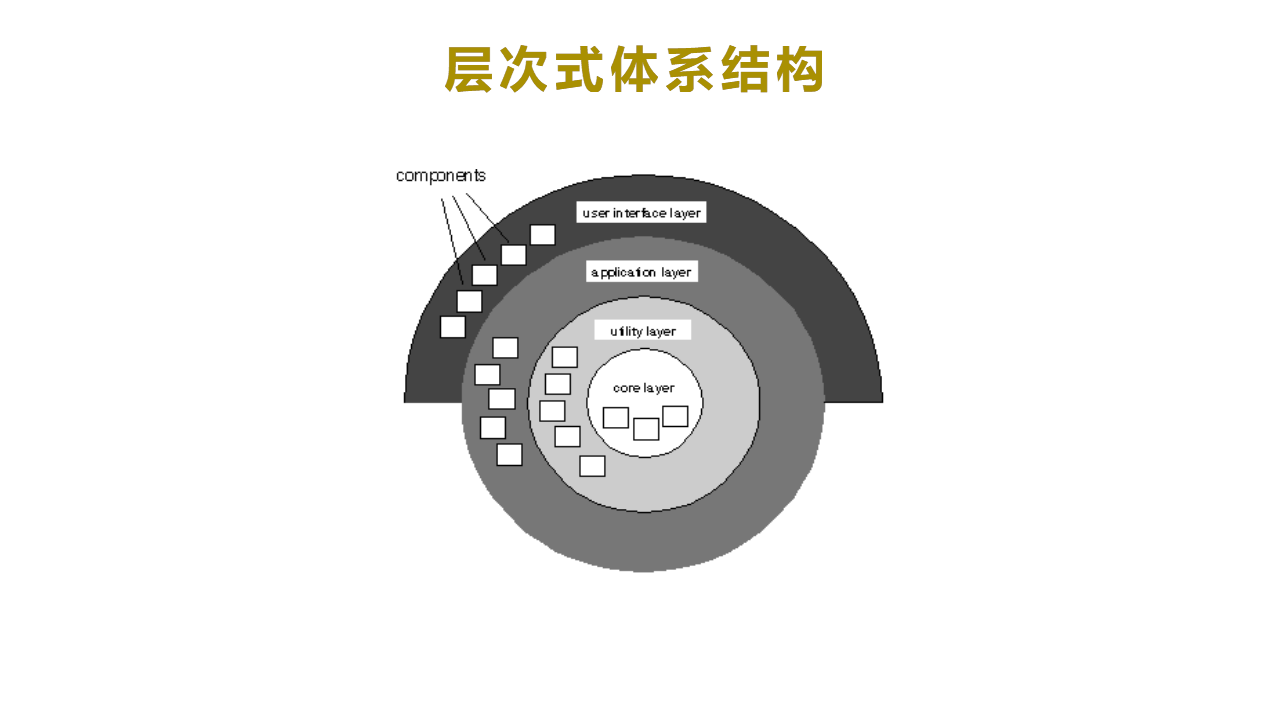
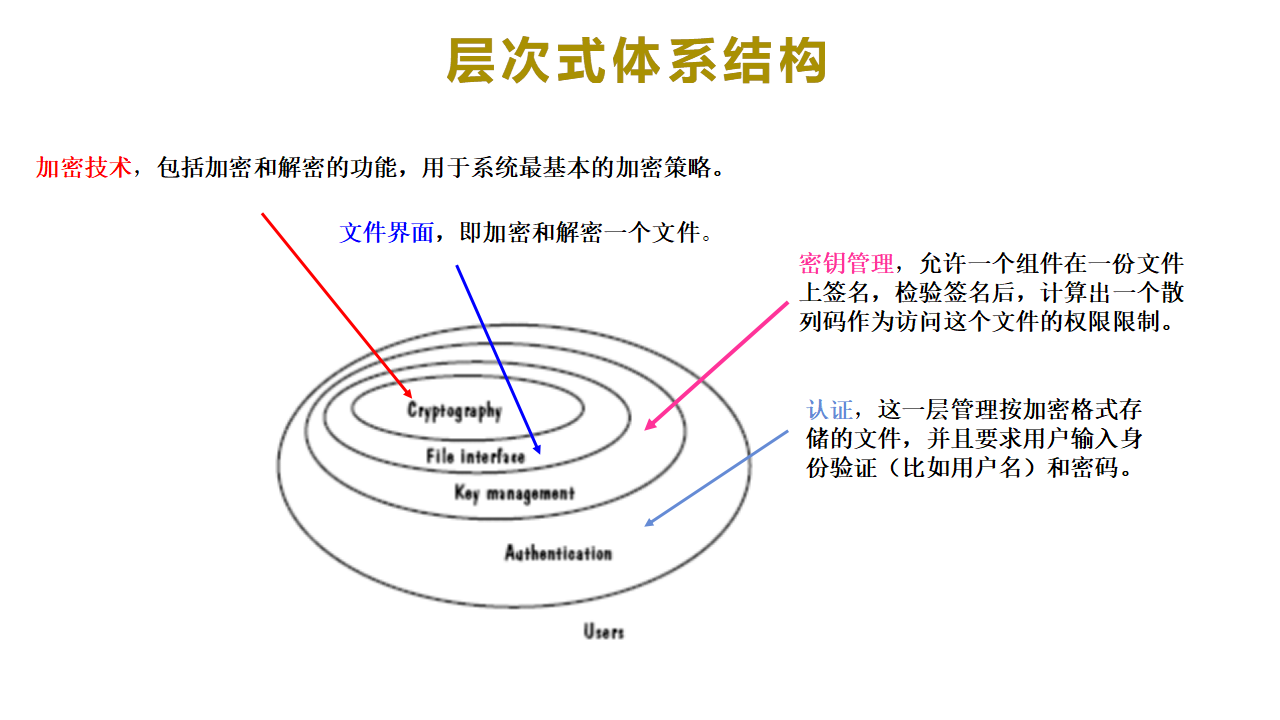
4)特点:
- 层次是分级的,每一层都为它外面的一层提供服务,而且对于它里面的一层来说是一个客户。
5)优点:
- 抽象概念——每一个层次都被认为是一个可扩展的抽象级,设计者可以用这些层次将一个问题分解成一系列更为抽象的步骤。
- 由于各层次间通讯的没有限制,当需求改变的时候,很容易增加或修改一个层次。通常,这样的改变只影响到相邻的两个层次。
- 重用一个层次也是非常简单的,只需要在相邻层次间做一些改变。
2、衡量体系结构复杂度
Card 和 Glass 系统复杂度的度量方法:
- $C=S+D$
- $S=\frac{1}{n}∑ f^2(i)$
- $D = \frac {V(i)}{[f(i)+1]}$
其中, S 是组件间的结构复杂度, D 是组件内部的数据复杂度, f(i) 是组件 i 的扇出, V(i) 是组件 i 的输入输出变量个数, n 是组件个数。
3、映射需求到软件体系结构
(1)步骤
从映射需求到软件体系结构需要经过以下步骤:
首先研究、分析和审查数据流图,对于发现的问题及时解决。
然后根据数据流图决定问题的类型。数据处理问题典型的类型有两种**:变换型和事务型**,针对这两种不同的类型分别进行分析处理。
由数据流图推导出系统的初始结构图。
利用一些启发式原则来改进系统的初始结构图,直到得到符合要求的结构图为止。
修改和补充数据词典。
制定测试计划。
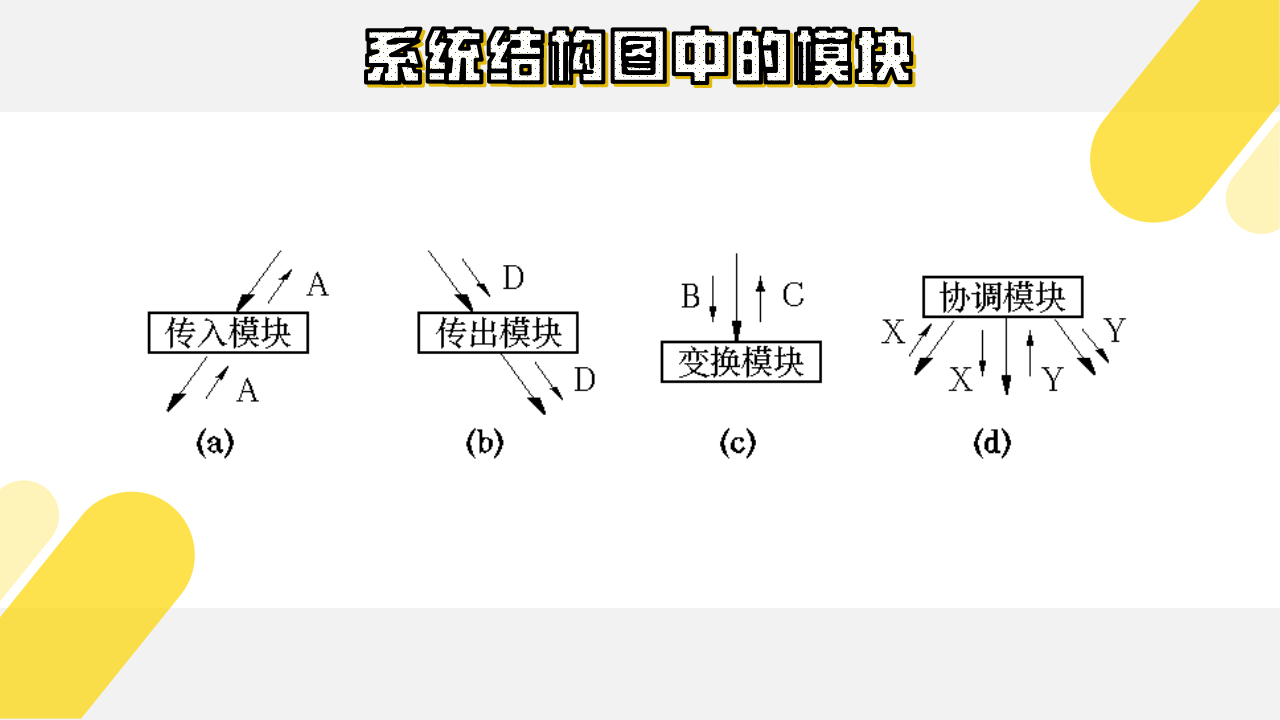
(2)系统结构图中的模块
- 传入模块 —— 从下属模块取得数据,经过某些处理,再将其传送给上级模块。它传送的数据流叫做逻辑输入数据流。
- 传出模块 —— 从上级模块获得数据,进行某些处理,再将其传送给下属模块。它传送的数据流叫做逻辑输出数据流。
- 变换模块 —— 它从上级模块取得数据,进行特定的处理,转换成其它形式,再传送回上级模块。它加工的数据流叫做变换数据流。
- 协调模块 —— 对所有下属模块进行协调和管理的模块。
如下图所示:
(3)变换型系统结构图
变换型数据处理问题的工作过程大致分为三步,如下图所示:
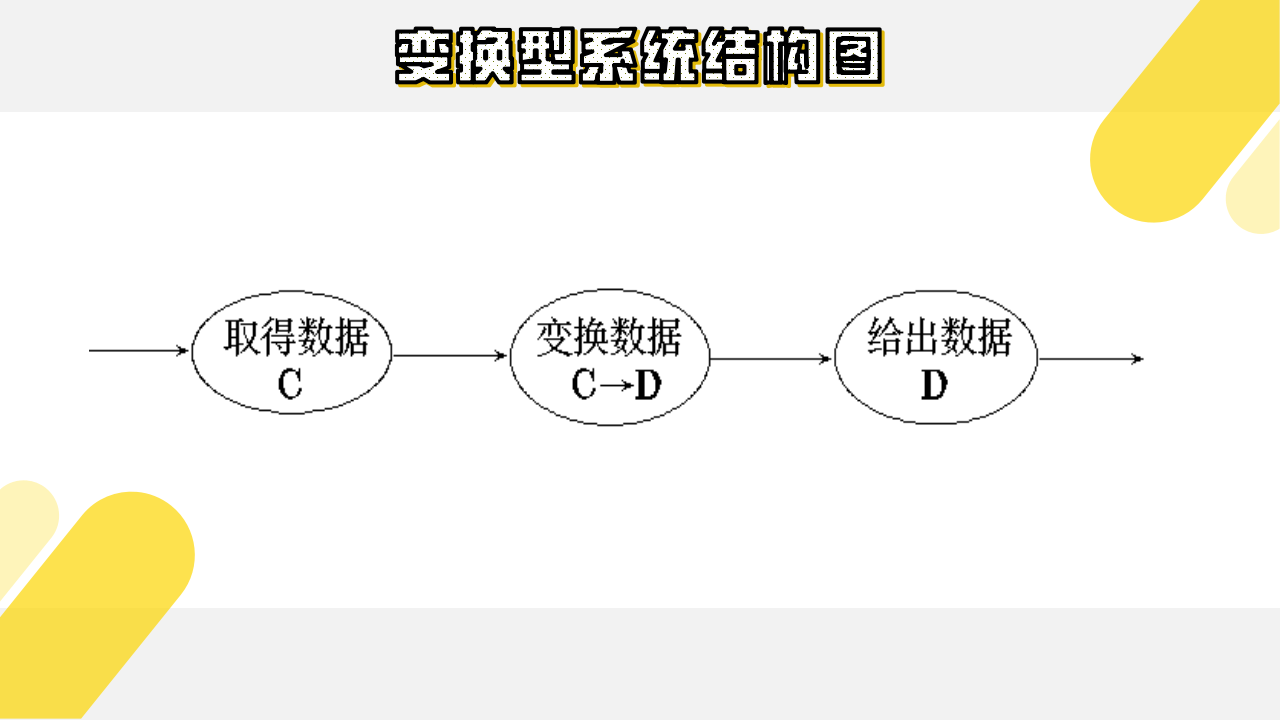
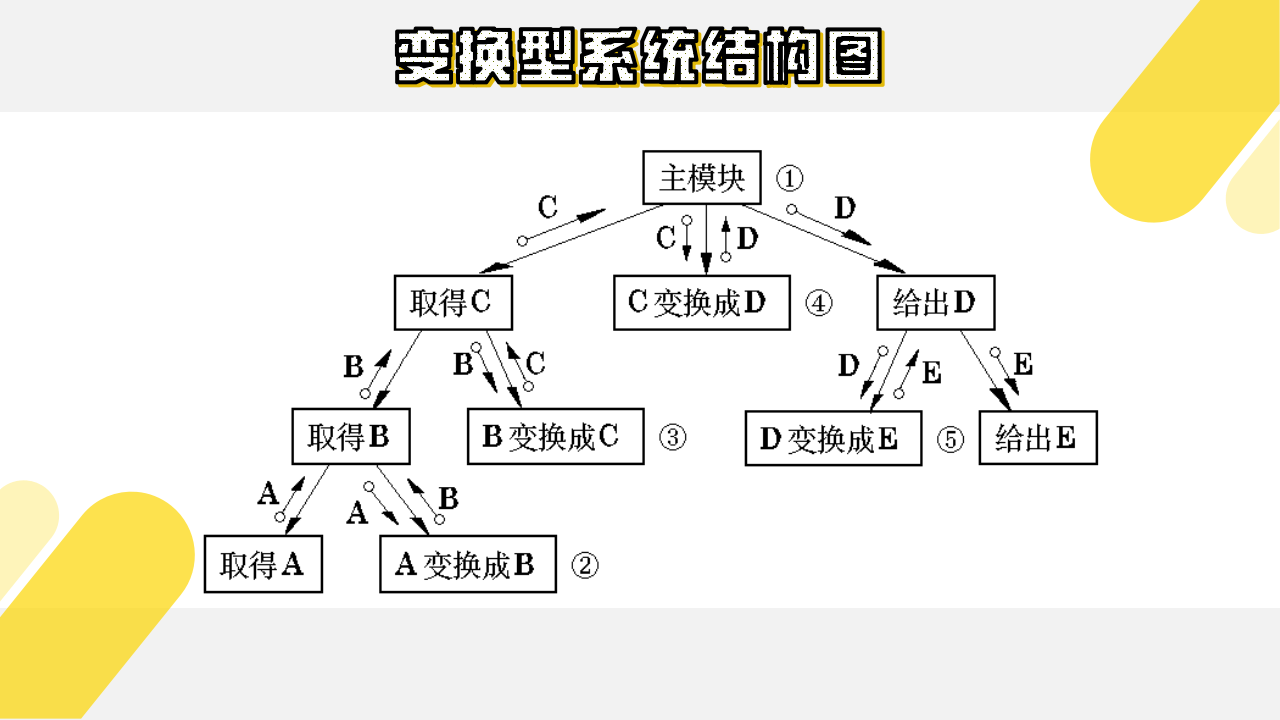
相应于取得数据、变换数据、给出数据,变换型系统结构图由输入、中心变换和输出等三部分组成。
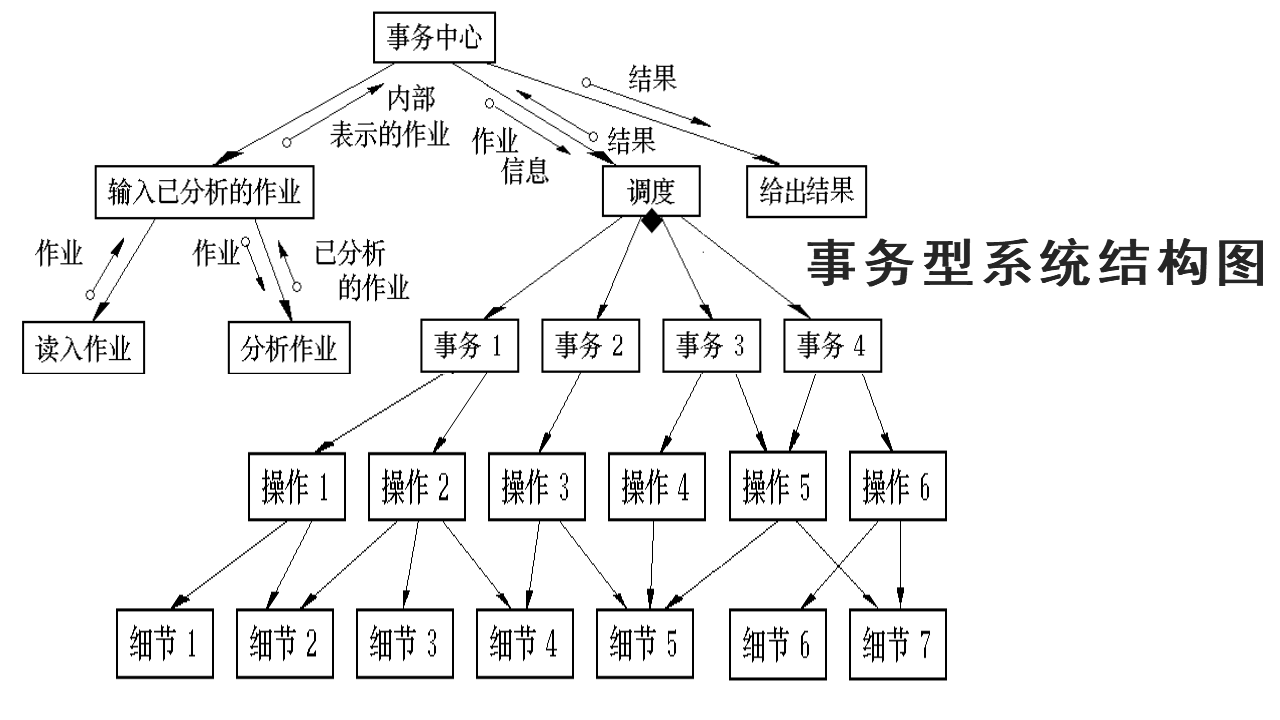
(4)事务型系统结构图
事务型系统接受一项事务,根据事务处理的特点和性质,选择分派一个适当的处理单元,然后给出结果。
事务中心模块按所接受的事务的类型,选择某一个事务处理模块执行,各事务处理模块并列。
每个事务处理模块可能要调用若干个操作模块,而操作模块又可能调用若干个细节模块。
(5)变换分析
1)变换分析方法由以下四部分组成:
- 重画数据流图;
- 区分有效(逻辑)输入、有效(逻辑)输出和中心变换部分;
- 进行一级分解,设计上层模块;
- 进行二级分解,设计输入、输出和中心变换部分的中、下层模块。
如图所示:
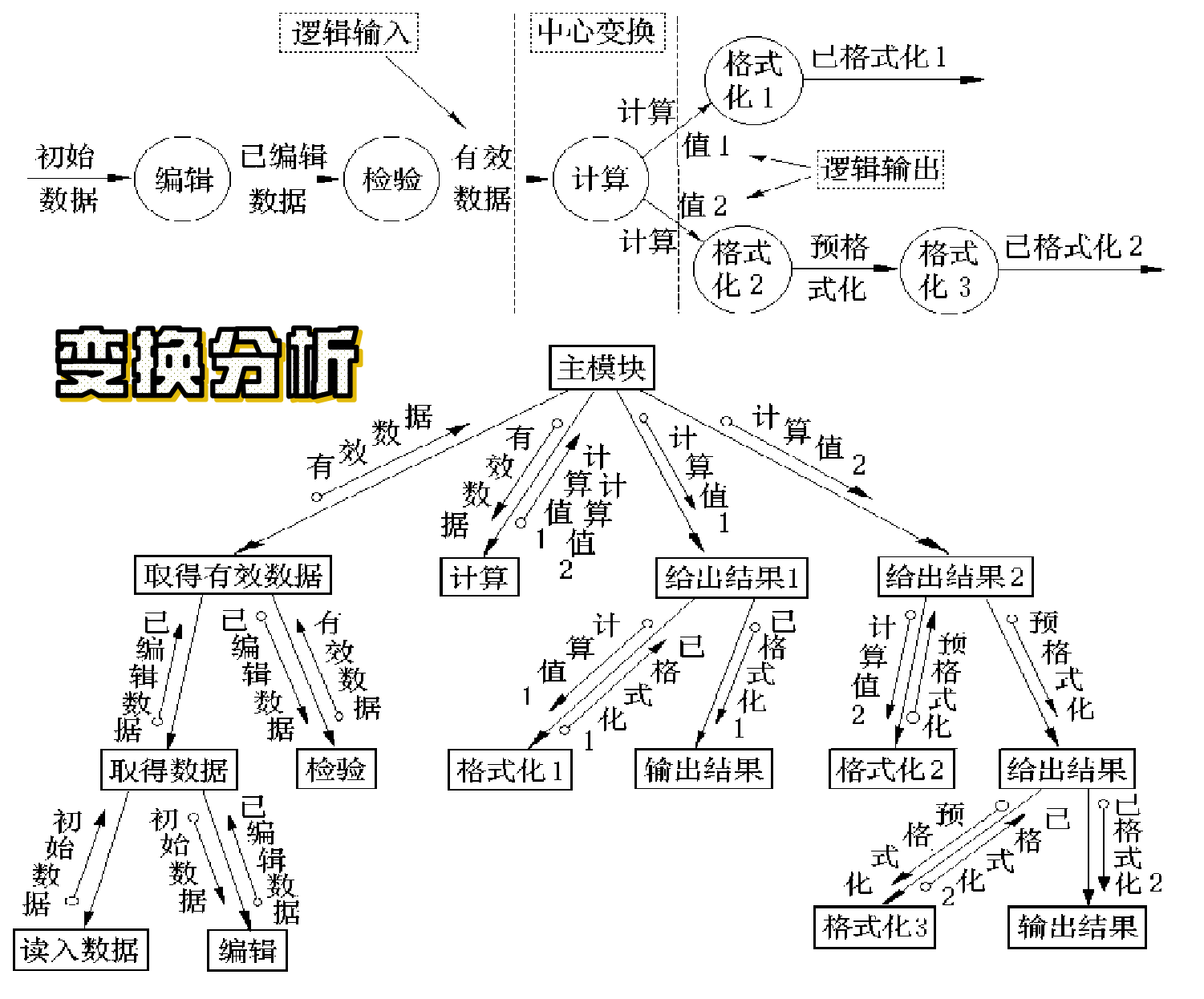
2)注意点
- 在选择模块设计的次序时,必须对一个模块的全部直接下属模块都设计完成之后,才能转向另一个模块的下层模块的设计。
- 在设计下层模块时,应考虑模块的耦合和内聚问题,以提高初始结构图的质量。
- 使用“黑箱”技术:在设计当前模块时,先把这个模块的所有下层模块定义成“黑箱”,在下一步就可以对它们进行设计和加工。这样,又会导致更多的“黑箱”。最后,全部“黑箱”的内容和结构应完全被确定。
- 在模块划分时,一个模块的直接下属模块一般在5 个左右。如果直接下属模块超过 10 个,可设立中间层次。
(6)事务分析
在很多软件应用中,存在某种作业数据流,它可以引发一个或多个处理,这些处理能够完成该作业要求的功能,这种数据流就叫做事务。
与变换分析一样,事务分析也是从分析数据流图开始,自顶向下,逐步分解,建立系统的结构图。
如下图所示:
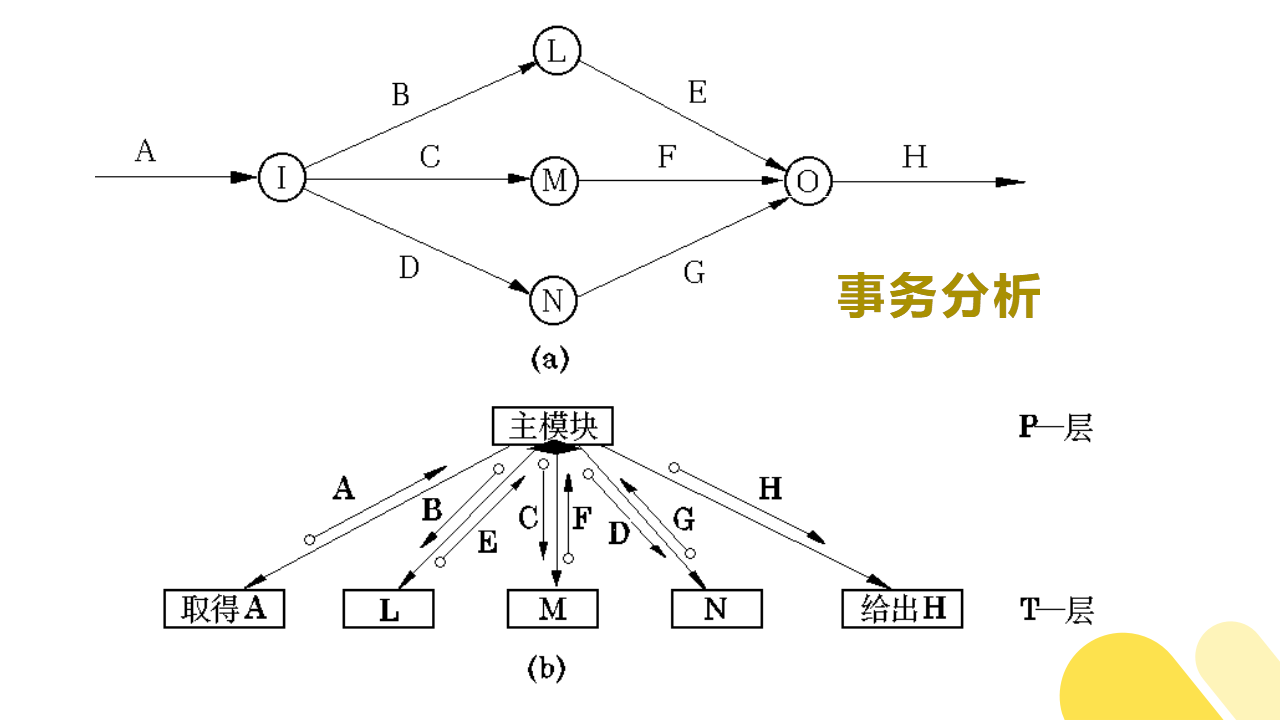
(7)混合结构
变换分析是软件系统结构设计的主要方法。
一般来说,一个大型的软件系统是变换型结构和事务型结构的混合结构。
所以,我们通常利用以变换分析为主,事务分析为辅的方式进行软件结构设计。
如下图所示:
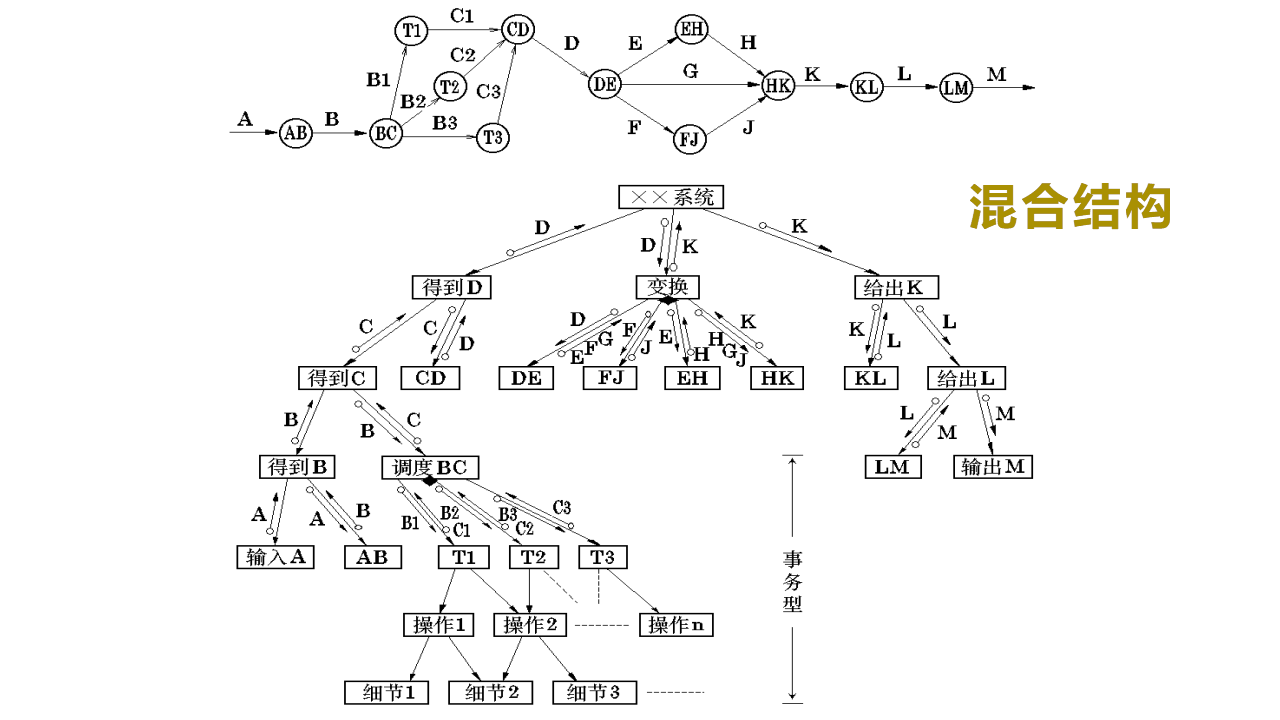
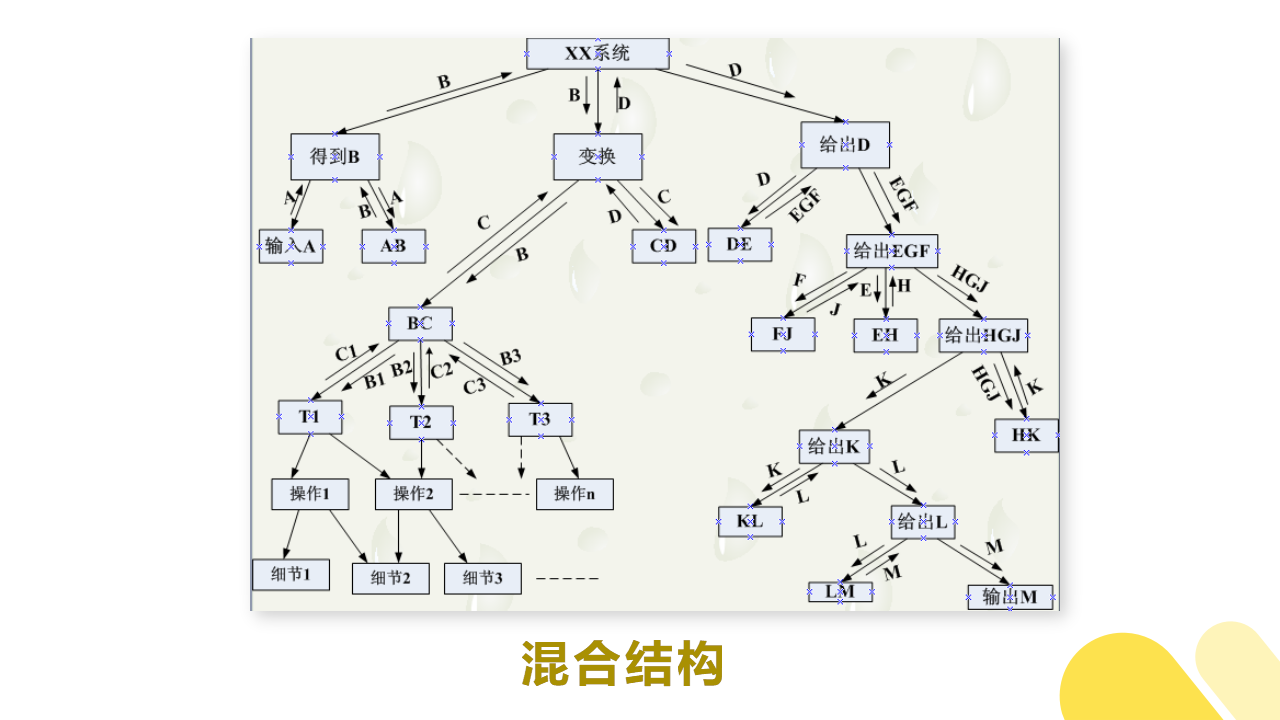
(8)软件模块结构的改进
1)模块功能的完善化
一个完整的模块应当有以下部分:
- 执行所规定功能的部分;
- 出错处理的部分。当模块不能完成所规定的功能时,必须回送出错标志,出现例外情况的原因。
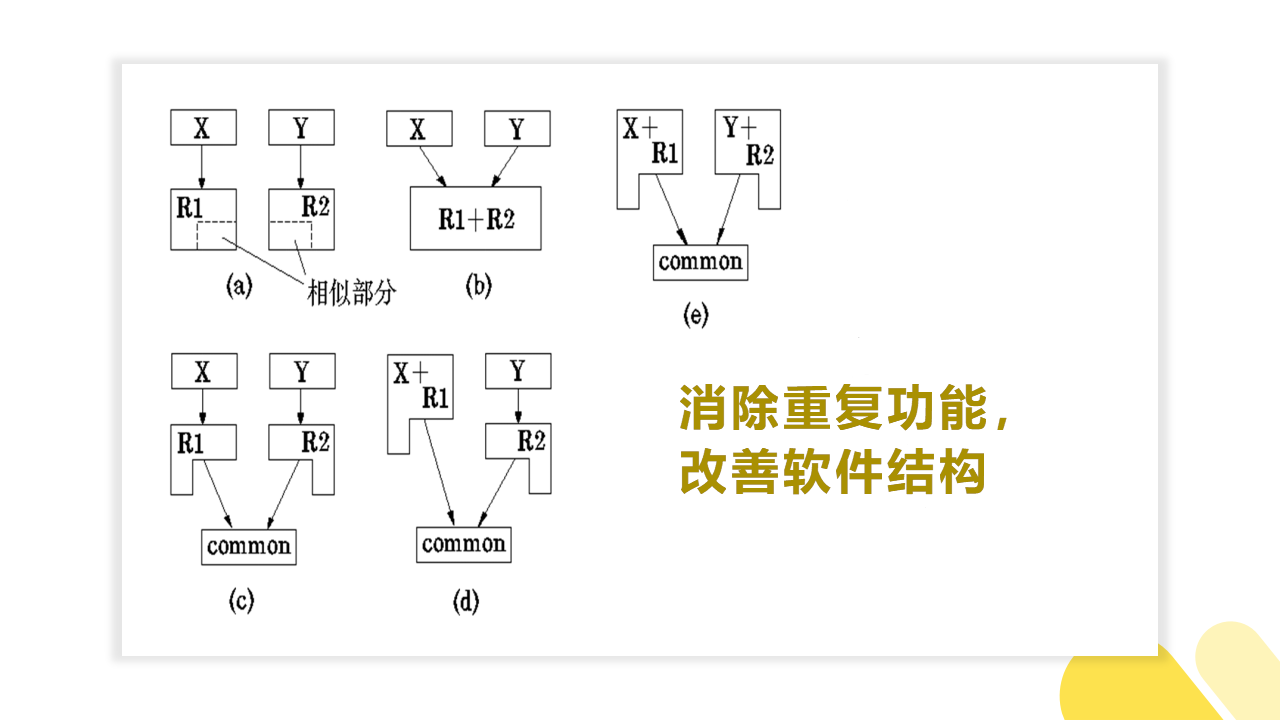
2)消除重复功能,改善软件结构
- 完全相似: 在结构上完全相似,可能只是在数据类型上不一致。此时可以采取完全合并的方法。
- 局部相似: 找出其相同部分,分离出去,重新定义成一个独立的下一层模块。还可以与它的上级模块合并。
如图所示:
3)模块的作用范围应在控制范围之内
- 模块的控制范围包括它本身及其所有的从属模块。
- 模块的作用范围是指模块内某一个判定的作用范围,凡是受这个判定影响的所有模块都属于这个判定的作用范围。
- 如果一个模块的作用范围包含在控制范围之内,则这种结构是简单的,否则,它的结构是不简单的。
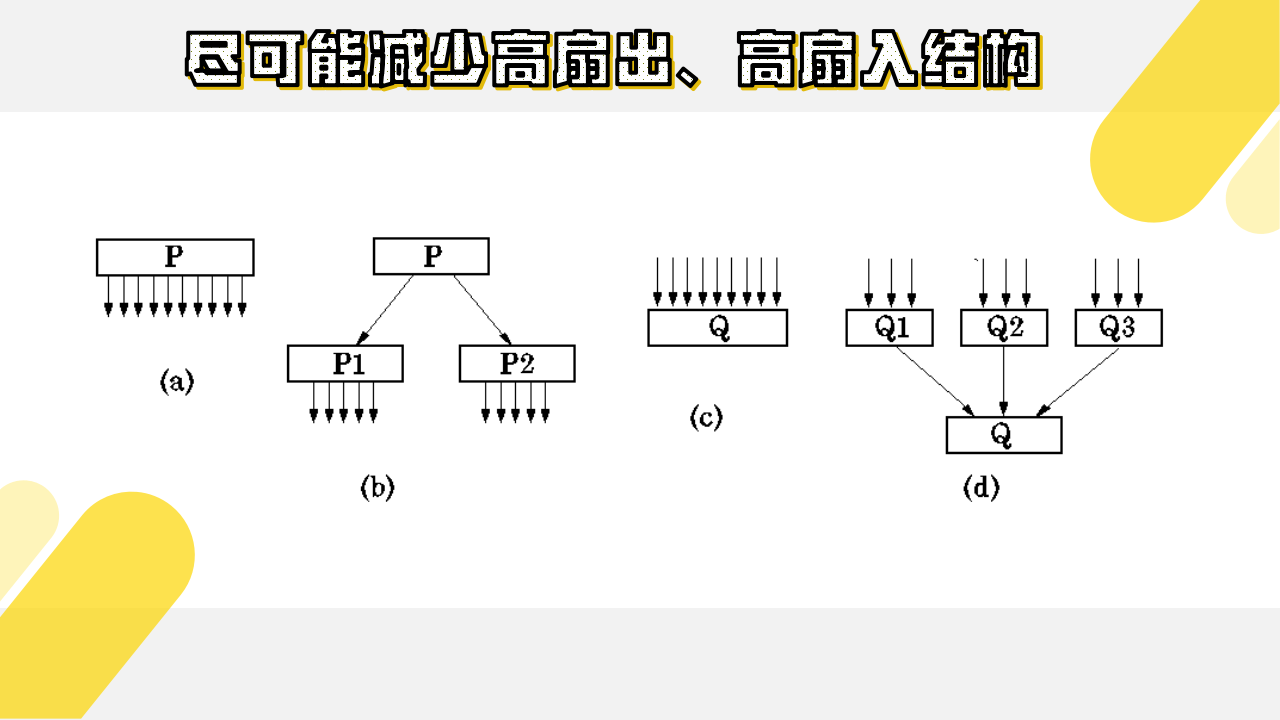
4)尽可能减少高扇出、高扇入结构
如果扇出数过大,就意味着该模块过分复杂,需要协调和控制过多的下属模块。应当适当增加中间层次的控制模块。
如图所示:
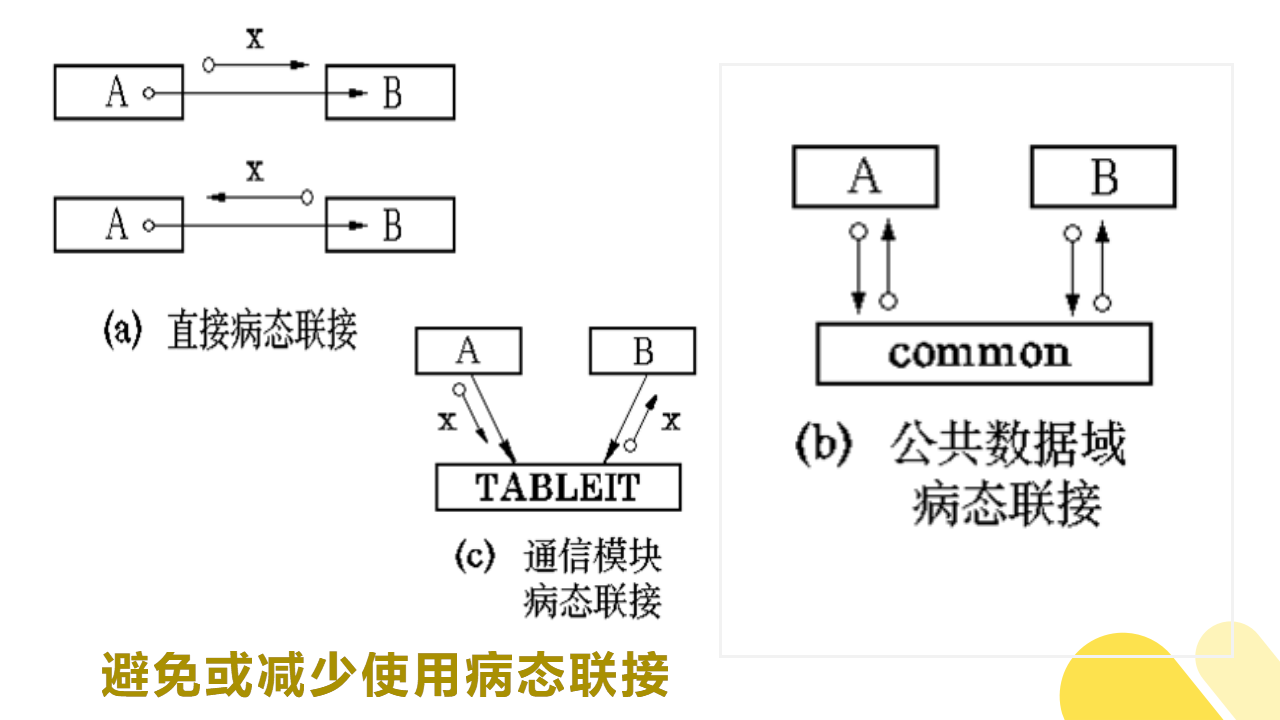
5)避免或减少使用病态联接
- 直接病态联接。
模块A直接从模块B内部取出某些数据,或者把某些数据直接送到模块B内部。 - 公共数据域病态联接。
A和B通过公共数据域,直接传送或接受数据,而不是通过它们的上级模块。这种方式将使得模块间的耦合程度剧增。它不仅影响模块A和模块B,同时也影响与公共数据域有关联的所有模块。 - 通信模块病态联接。 即
模块A和模块B通过通信模块TABLEIT传送数据。从表面看,这不是病态联接,因为模块A和模块B都未涉及通信模块TABLEIT的内部。 然而,它们之间的通信没有通过它们的上级模块。从这个意义上来讲,这种连接是病态的。
如图所示:
6)模块的大小要适中
- 模块的大小,可以用模块中所含语句数量的多少来衡量。
- 把模块的大小限制在一定的范围之内。通常规定其语句行数在 50 ~ 100 左右,保持在一页纸之内,最多不超过 500 行。
五、数据库设计
1、数据模式需满足的条件
建立一个数据模式,必须满足的几个条件:
- 符合用户的要求。
- 与所选用的
DBMS所支持的数据模式相匹配。 - 数据组织合理,应易操作,易维护,易理解。
2、数据的规范化形式
(1)非规范化形式示例
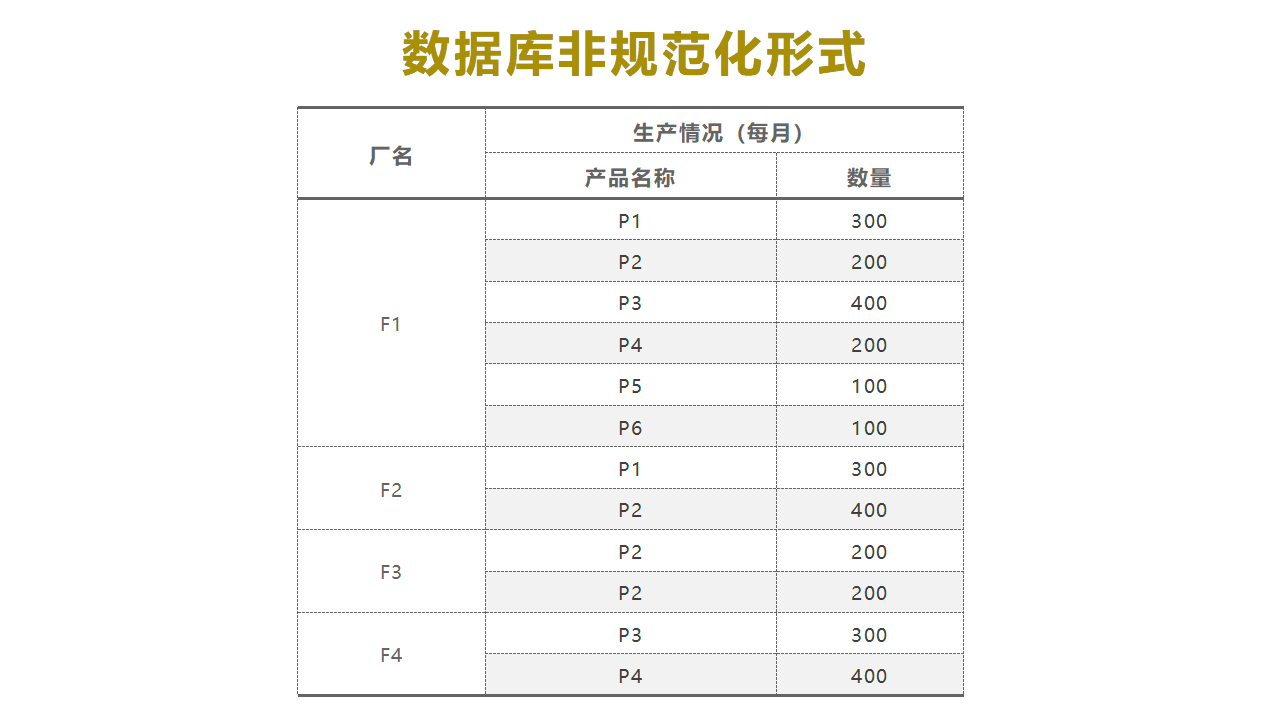
(2)数据的规范化形式
- 在任一列上,数据项应该具有同一个属性。
- 在这个表中所有的行都是不相同的,即不允许有重复的组项出现。
- 在一个表中,行的顺序是无关紧要的。
- 在一个表中,每一个列(属性)有不同的名称,列的顺序也无关紧要。
(3)数据库的三大范式
1)第一范式: 消除组合项
2)第二范式: 消除非主属性对主关键字的不完全依赖性
3)第三范式: 消除传递依赖
六、处理过程设计
1、处理过程设计是什么?
从软件开发的工程化观点来看,在编制程序以前,需要对所采用算法的逻辑关系进行分析,设计出全部必要的过程细节,并给予清晰的表达。这就是过程设计的任务。
2、处理过程设计的方法
在过程设计阶段中,需要要决定各个模块的实现算法,并精确地表达这些算法。而表达过程规格说明的工具叫做详细设计工具,它可以分为 图形工具 、 表格工具 和 语言工具 三大类。那么处理过程设计主要有以下四种方法:
- 程序流程图
- N-S 盒图
- PAD 问题分析图
- 伪代码
(1)程序流程图
程序流程图也称为程序框图,程序流程图使用五种基本控制结构,分别是:
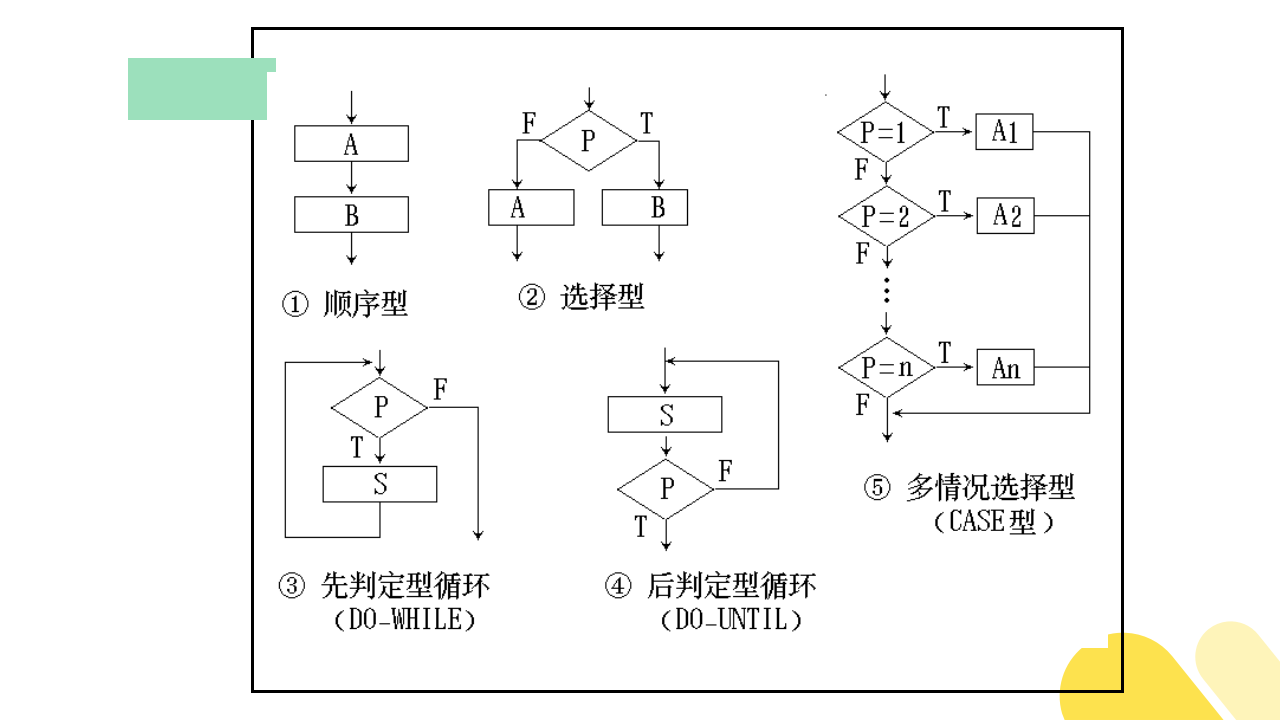
程序流程图的示例图如下图所示:

(2)N-S 图(盒图)
N-S 图也叫做盒图,其五种基本控制结构由五种图形构件表示,分别是:
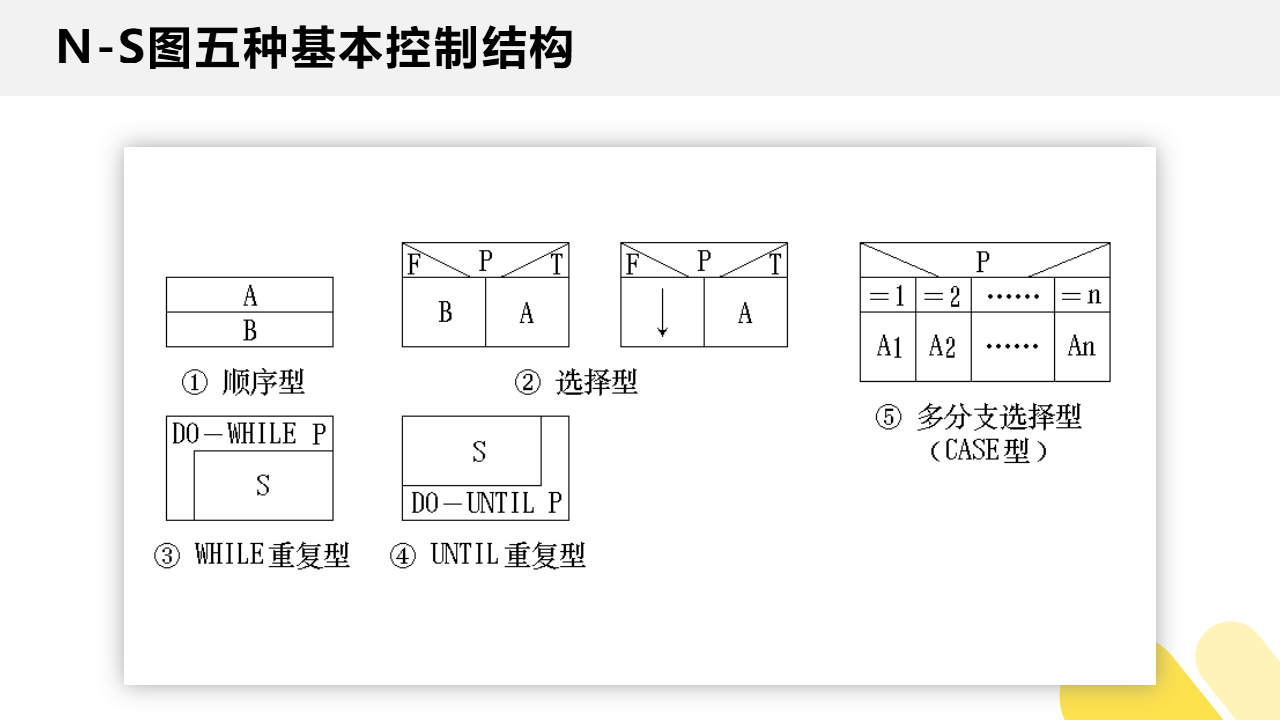
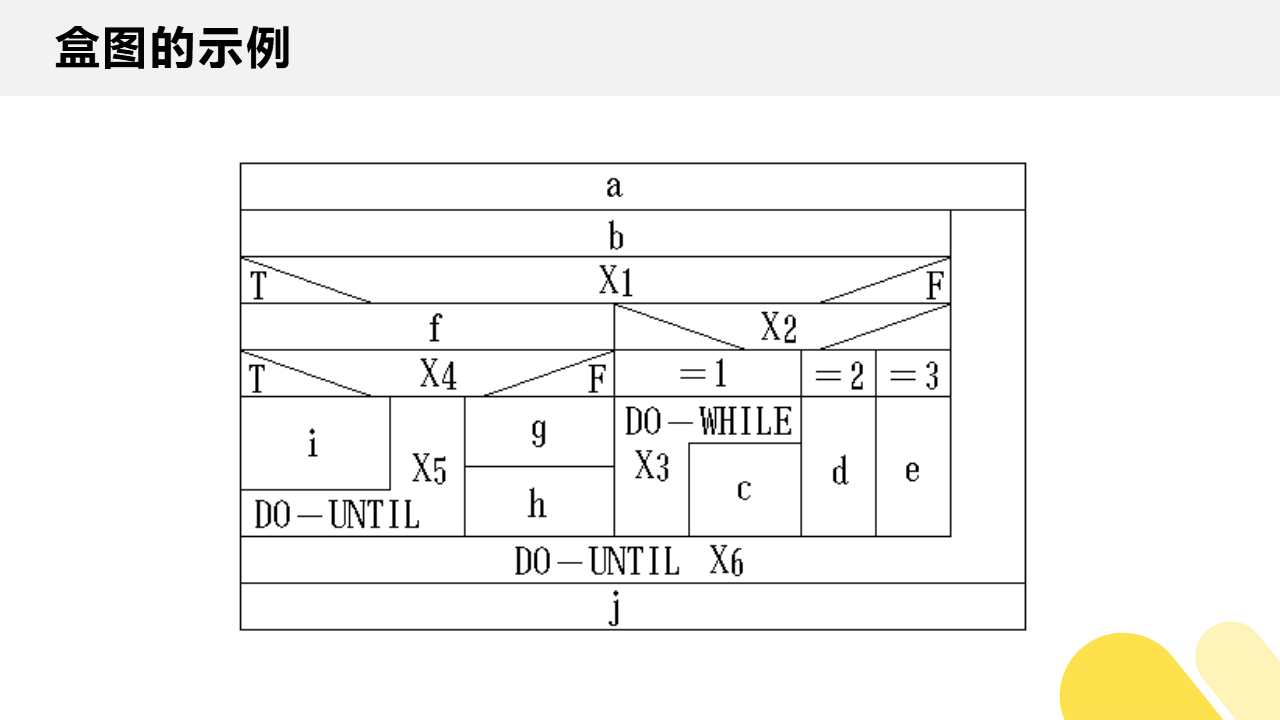
盒图的示例图如下图所示:
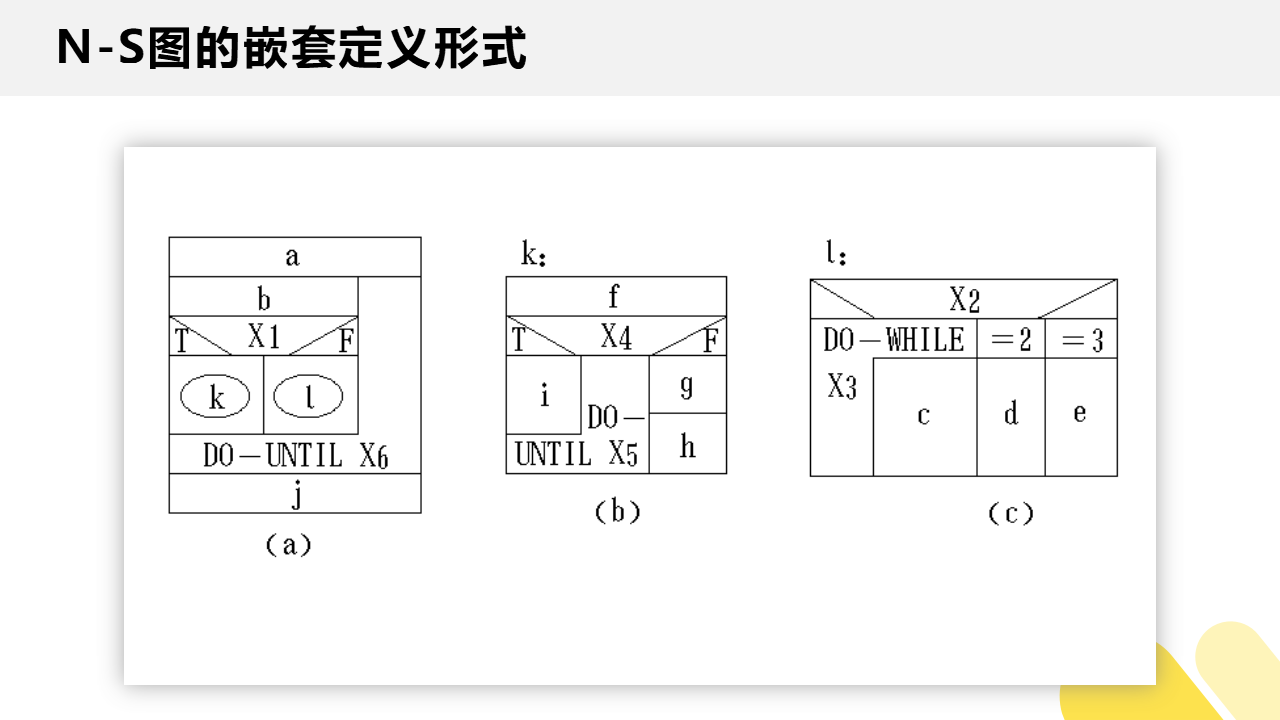
N-S 图的嵌套定义形式:
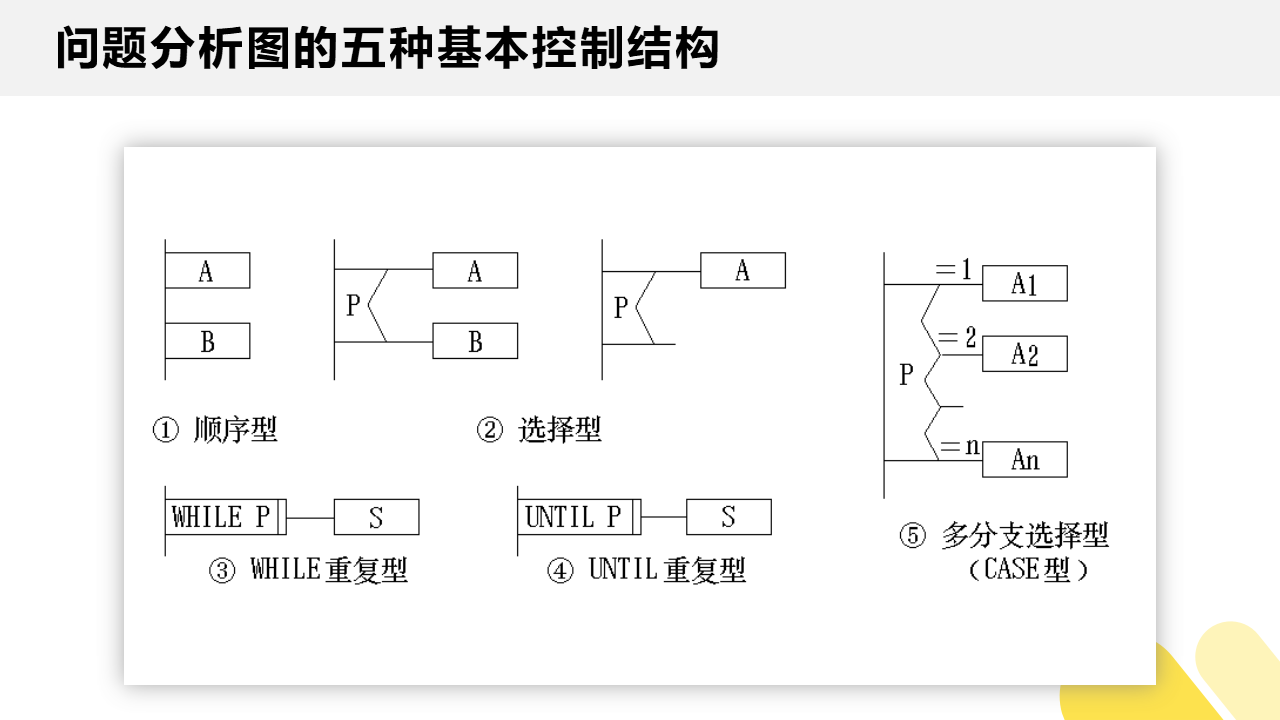
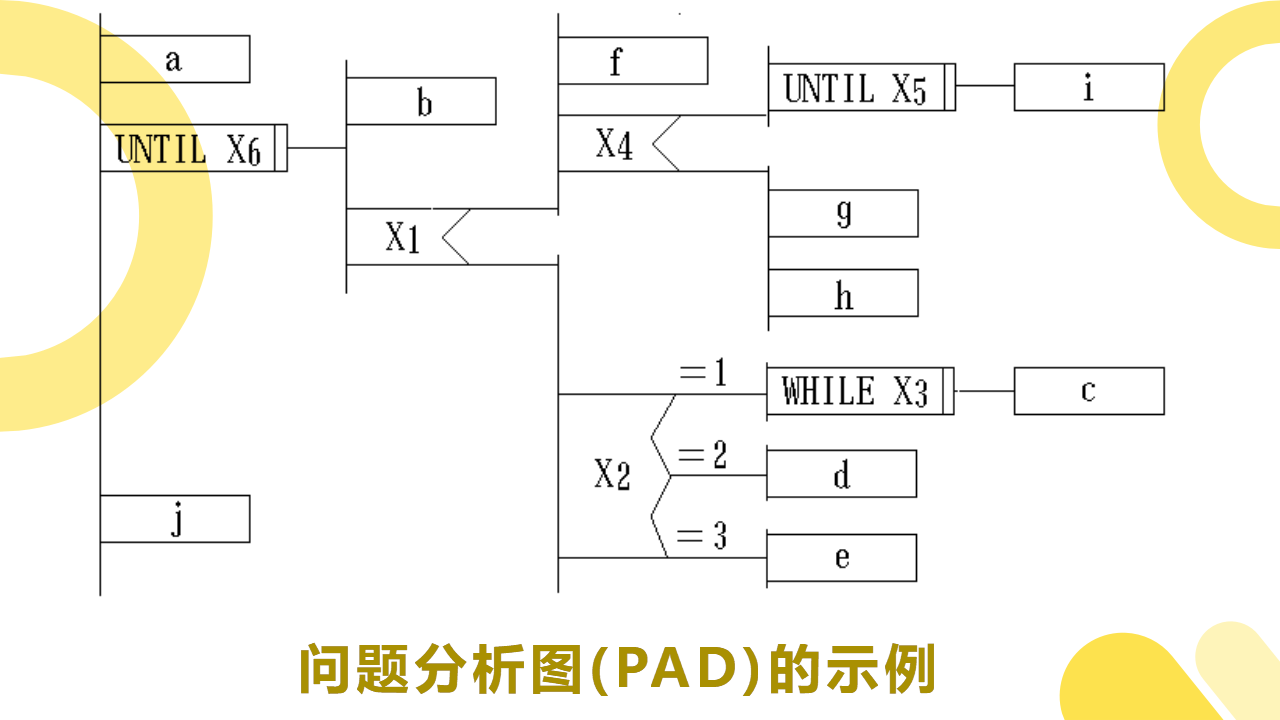
(3)问题分析图(PAD)
PAD 也设置了五种基本控制结构的图式,并允许递归使用。分别是:
问题分析图(PAD)的示例图如下图所示:
(4)伪代码
1)伪代码是什么
伪代码,及程序设计语言,也称 PDL (Program Design Language) 。
PDL 是一种用于描述功能模块的算法设计和加工细节的语言,称为程序设计语言,它是一种伪码。
伪码的语法规则分为“外语法”和“内语法”。
PDL 具有严格的关键字外语法,用于定义控制结构和数据结构,同时它表示实际操作和条件的内语法时可使用自然语言的词汇。
2)PDL 的特点
- 提供全部结构化控制结构、数据说明和模块特征。能对
PDL正文进行结构分割,使之变得易于理解。 - 为了区别关键字,规定关键字一律大写,其它单词一律小写。或者规定关键字加下划线,或者规定它们为黑体字。
- 内语法使用自然语言来描述处理特性。内语法比较灵活,只要写清楚就可以,不必考虑语法错误,以利于人们可把主要精力放在描述算法的逻辑上。
- 有数据说明机制,包括简单的(如标量和数组)与复杂的(如链表和层次结构)的数据结构。
- 有子程序定义与调用机制,用以表达各种方式的接口说明。
3)举例
比如:示范一个拼词检查程序,流程如下代码所示,请写出该程序的伪代码。
PROCEDURE spellcheck IS
BEGIN
split document into single words
look up words in dictionary
display words which are not in dictionary
create a new dictionary
END spellcheckPROCEDURE spellcheck IS
BEGIN
split document into single words
look up words in dictionary
display words which are not in dictionary
create a new dictionary
END spellcheckAnswer:
使用 PDL 语言,逐步求精:
PROCEDURE spellcheck
BEGIN
--* split document into single words
LOOP get next word
add word to word list in sortorder
EXIT WHEN all words processed
END LOOP
--* look up words in dictionary
LOOP get word from word list
IF word not in dictionary THEN
--* display words not in dictionary
display word
prompt on user terminal
IF user response says word OK THEN
add word to good word list
ELSE
add word to bad word list
ENDIF
ENDIF
EXIT WHEN all words processed
END LOOP
--* create a new words dictionary
dictionary :=
merge dictionary and good word list
END spellcheckPROCEDURE spellcheck
BEGIN
--* split document into single words
LOOP get next word
add word to word list in sortorder
EXIT WHEN all words processed
END LOOP
--* look up words in dictionary
LOOP get word from word list
IF word not in dictionary THEN
--* display words not in dictionary
display word
prompt on user terminal
IF user response says word OK THEN
add word to good word list
ELSE
add word to bad word list
ENDIF
ENDIF
EXIT WHEN all words processed
END LOOP
--* create a new words dictionary
dictionary :=
merge dictionary and good word list
END spellcheck七、界面设计
界面设计也称为接口设计,需了解3 条黄金规则:
- 用户控制界面;
- 减轻用户记忆负担;
- 保持界面一致。
八、写在最后
从结构化系统分析到结构化系统设计,我们解决了 从软件“做什么”到软件“怎么做” 的问题。相信大家对结构化系统设计的内容也有了一个新的了解🙋
结构化系统设计的内容就讲到这里啦!如有需要了解软件工程相关的其他内容,可到『软件工程』栏目进行查看学习~